---
title: "Análisis de Fiabilidad y Factorial Confirmatorio (AFC)"
format: html
---
## Introducción al análisis de fiabilidad de escalas
En nuestro viaje a través del análisis de datos, hemos trabajado con una multitud de variables: esperanza de vida, percepciones sobre un smartphone, clase social, etc. Algunas de estas variables son directamente observables y fáciles de medir (como la edad o el precio). Sin embargo, muchos de los conceptos más interesantes en marketing, psicología o sociología son abstractos e inobservables. No podemos medir directamente la "lealtad a la marca", la "satisfacción del cliente" o la "calidad percibida del servicio". A estos conceptos teóricos los llamamos **constructos latentes**.
Para medir estos constructos, recurrimos a la creación de **escalas de medida**: un conjunto de ítems o preguntas (las variables observadas) diseñadas para capturar en conjunto la esencia del constructo latente. Por ejemplo, para medir la "satisfacción", podríamos preguntar sobre la "satisfacción general", la "probabilidad de recomendar" y si "la elección fue acertada".
Pero, ¿cómo sabemos si nuestro instrumento de medida —nuestra escala— es bueno? ¿Cómo podemos estar seguros de que las preguntas que hemos diseñado funcionan juntas de manera coherente para medir lo que queremos medir? Antes de poder afirmar que nuestra escala es *válida* (es decir, que mide realmente el constructo correcto), primero debemos asegurar que es **fiable**. El **análisis de fiabilidad** es el proceso estadístico que nos permite evaluar la calidad y consistencia de nuestras escalas de medida.
## Fundamentos teóricos: la teoría clásica de los tests
La base de todo análisis de fiabilidad reside en la Teoría Clásica de los Tests (TCT). Su postulado fundamental es simple pero profundo: la puntuación que observamos para un individuo en un ítem o una escala (X) se compone de dos partes: su **puntuación verdadera** (T), que es el valor real e inobservable del constructo, y un **error de medida** (E) [@Cronbach1951].
**X = T + E**
El error de medida (E) es el "ruido" aleatorio que distorsiona nuestra medición. Puede deberse a la ambigüedad de una pregunta, al estado de ánimo del encuestado, a errores de transcripción, etc. El objetivo de un buen instrumento de medida es minimizar este error.
En este contexto, la **fiabilidad** se define como la proporción de la varianza total de la puntuación observada (X) que se debe a la varianza de la puntuación verdadera (T). En otras palabras, es una medida de cuánta de la "señal" (puntuación verdadera) capturamos en relación con el "ruido" (error). Una escala perfectamente fiable sería aquella en la que todo lo que medimos es la puntuación verdadera, sin nada de error.
## La consistencia interna: el pilar de la fiabilidad
Existen diferentes tipos de fiabilidad (test-retest, formas paralelas, etc.), pero en la investigación social y de mercados, la más utilizada con diferencia es la **fiabilidad de consistencia interna**. Esta evalúa hasta qué punto los ítems de una escala están interrelacionados y miden el mismo constructo subyacente. La idea es que si todas las preguntas de una escala están diseñando para medir la "satisfacción", las respuestas de un individuo a esas preguntas deberían ser consistentes entre sí.
### Alfa de Cronbach (α): el indicador clásico
El indicador más famoso y extendido para medir la consistencia interna es el **Alfa de Cronbach (α)**. Conceptualmente, el Alfa de Cronbach puede entenderse como una medida del promedio de todas las posibles correlaciones entre los ítems que componen una escala, ajustado por el número de ítems. Su valor oscila entre 0 y 1.
La interpretación de su valor sigue unas reglas generales ampliamente aceptadas [@Hair2019]:
- **α > 0.90:** Excelente
- **α > 0.80:** Bueno
- **α > 0.70:** Aceptable (es el umbral más comúnmente utilizado en la investigación)
- **α > 0.60:** Cuestionable (podría ser aceptable en análisis exploratorios)
- **α < 0.60:** Pobre o Inaceptable
Es crucial entender lo que el Alfa de Cronbach **no** es: **no es una medida de unidimensionalidad**. Un valor alto de alfa nos dice que los ítems son consistentes entre sí, pero no nos garantiza que estén midiendo un único constructo. Una escala que mida simultáneamente "satisfacción" y "lealtad" podría tener un alfa alto si ambos constructos están correlacionados. La cuestión de la unidimensionalidad es un problema de **validez**, que se aborda con el Análisis Factorial (tanto exploratorio como confirmatorio).
### Más allá del alfa: omega de McDonald (ω)
Aunque el Alfa de Cronbach es omnipresente, se basa en un supuesto bastante estricto conocido como "tau-equivalencia", que implica que todos los ítems miden el constructo con la misma precisión (es decir, tienen cargas factoriales iguales). Cuando este supuesto se viola (lo cual es muy común), el alfa puede subestimar la fiabilidad real de la escala.
Por esta razón, en la literatura metodológica moderna se recomienda cada vez más el uso del **Omega de McDonald (ω)** como una alternativa superior [@Dunn2014]. El coeficiente omega no requiere el supuesto de tau-equivalencia y se basa en las cargas factoriales de los ítems, proporcionando una estimación más realista de la fiabilidad. Su interpretación es similar a la del alfa, con los mismos umbrales de aceptabilidad.
## Diagnóstico y mejora de la escala: las estadísticas ítem-total
El análisis de fiabilidad no solo nos da un valor global para la escala, sino que también nos proporciona diagnósticos para cada ítem individual, permitiéndonos identificar y eliminar aquellos que no funcionan bien. Las dos estadísticas más importantes son:
1. **Correlación Ítem-Total Corregida:** Esta estadística mide la correlación de un ítem específico con la puntuación total de la escala, calculada a partir de *todos los demás ítems*. Nos dice qué tan bien "encaja" cada ítem en el conjunto. Un ítem que mide el mismo constructo que los demás debería tener una correlación alta con la puntuación total. Los ítems con una correlación ítem-total corregida **inferior a 0.30** suelen ser considerados problemáticos y son candidatos a ser eliminados [@Field2018].
2. **Alfa si se Elimina el Ítem:** Para cada ítem, el software calcula cuál sería el valor del Alfa de Cronbach de la escala si ese ítem en particular fuera eliminado. Esta es una herramienta de diagnóstico muy poderosa:
* Si al eliminar un ítem, el valor del alfa **aumenta significativamente**, es una señal clara de que ese ítem es un "mal elemento" que está reduciendo la consistencia interna de la escala. Deberíamos considerar seriamente su eliminación.
* Si al eliminar un ítem, el valor del alfa disminuye, significa que el ítem está contribuyendo positivamente a la fiabilidad de la escala y debería ser mantenido.
## El puente hacia el análisis factorial confirmatorio
Realizar un análisis de fiabilidad es el primer paso obligatorio en la validación de una escala de medida. Nos asegura que nuestro instrumento de medición es **consistente y preciso**. Si una escala no es fiable, no puede ser válida. Es como tener una báscula que da un peso diferente cada vez que nos subimos; antes de preocuparnos si la báscula está bien calibrada (validez), debemos asegurarnos de que al menos da siempre la misma lectura (fiabilidad).
Una vez que hemos depurado nuestra escala y hemos demostrado que tiene una alta consistencia interna (un alfa u omega aceptable), estamos listos para dar el siguiente paso: el **Análisis Factorial Confirmatorio (AFC)**. Con el AFC, pasaremos de la pregunta "¿Miden mis ítems algo de manera consistente?" a la pregunta "¿Miden mis ítems el constructo único que yo creo que están midiendo?". La fiabilidad nos da la confianza en nuestro instrumento; el AFC nos dará la confianza en nuestra teoría.
¡Excelente! Es el momento de poner en práctica la teoría de la fiabilidad. Este caso práctico está diseñado para ser un tutorial completo que no solo muestre cómo calcular la fiabilidad, sino también cómo diagnosticar y purificar una escala, un proceso fundamental en la investigación real.
Además, como solicitaste, la estructura de los datos simulados se basará en un constructo latente, lo que establecerá una base perfecta y coherente para la posterior introducción al Análisis Factorial Confirmatorio.
## Aplicación práctica: validación de una escala de satisfacción del cliente
Para nuestro caso práctico, nos pondremos en el rol de un investigador de mercados que ha diseñado una encuesta para medir la "Satisfacción del Cliente" con un nuevo servicio de streaming. El objetivo es validar si la escala de medida propuesta es fiable.
### Objetivo de la investigación
El objetivo de este análisis es:
> **Evaluar la fiabilidad de consistencia interna de una escala de 5 ítems diseñada para medir el constructo latente "Satisfacción del Cliente". El proceso incluirá el diagnóstico de ítems problemáticos, la purificación de la escala si fuera necesario, y el cálculo de los indicadores de fiabilidad finales.**
### Preparación de los datos
Hemos realizado una encuesta a 300 clientes. La escala inicial consta de 5 ítems medidos en una escala de 1 a 10. Cuatro de estos ítems fueron diseñados para medir directamente la satisfacción, mientras que un quinto ítem es una variable aleatoria incluida para actuar como un "distractor" y poner a prueba nuestro proceso de diagnóstico.
Simularemos los datos partiendo de un constructo latente de "Satisfacción" para asegurar una estructura realista y reproducible.
```{r setup-datos-fiabilidad-final}
# Para que el ejemplo sea reproducible de forma exacta
set.seed(42)
n <- 300
# 1. Creamos la variable latente subyacente "Satisfacción"
latent_satisfaction <- rnorm(n, 0, 1)
# 2. Generamos los ítems observados
# Cuatro ítems fuertemente relacionados con la satisfacción
datos_satisfaccion <- data.frame(
SAT1_General = 7 + 0.85 * latent_satisfaction + rnorm(n, 0, 0.5),
SAT2_Expectativas = 7 + 0.80 * latent_satisfaction + rnorm(n, 0, 0.6),
SAT3_Ideal = 7 + 0.90 * latent_satisfaction + rnorm(n, 0, 0.4),
SAT4_Recomendacion = 7 + 0.82 * latent_satisfaction + rnorm(n, 0, 0.5),
# Un ítem que es puro ruido aleatorio, no relacionado con la satisfacción
Ruido_Aleatorio = 5 + rnorm(n, 0, 2.0)
)
# 3. Aseguramos que los datos están en la escala 1-10
datos_satisfaccion <- as.data.frame(lapply(datos_satisfaccion, function(x) round(pmin(10, pmax(1, x)))))
# Vistazo inicial a los datos
head(datos_satisfaccion)
```
### Ejecución y diagnóstico del análisis de fiabilidad
Utilizaremos el paquete `psych`, que es el estándar de oro en R para este tipo de análisis.
#### Paso 1: análisis de fiabilidad de la escala inicial (5 ítems)
Calcularemos el Alfa de Cronbach y las estadísticas ítem-total para la escala completa.
```{r analisis-fiabilidad-inicial-final}
# Cargamos el paquete
library(psych)
# Ejecutamos el análisis de fiabilidad
alpha_inicial <- alpha(datos_satisfaccion)
# Mostramos los resultados completos
print(alpha_inicial, digits = 2)
```
**Interpretación de los resultados iniciales:**
1. **Fiabilidad Global (raw_alpha):** El Alfa de Cronbach es de **`r round(alpha_inicial$total$raw_alpha, 2)`**. Según nuestros umbrales, este valor es "Aceptable", pero no alcanza el nivel de "Bueno" (0.80), lo que sugiere que la escala puede ser mejorada.
2. **Estadísticas Ítem-Total (item.stats):** Esta tabla es la clave para el diagnóstico.
* **Correlación Ítem-Total Corregida (`r.cor`):**
* Los primeros cuatro ítems (`SAT1` a `SAT4`) tienen correlaciones muy altas y positivas con el resto de la escala, muy por encima del umbral de 0.30. Esto indica que encajan perfectamente.
* Sin embargo, el ítem `Ruido_Aleatorio` tiene una correlación de **`r round(alpha_inicial$item.stats["Ruido_Aleatorio", "r.cor"], 2)`**. Este valor es prácticamente cero, una señal inequívoca de que este ítem no mide lo mismo que los demás.
* **Alfa si se Elimina el Ítem (`alpha.drop`):**
* Si eliminamos cualquiera de los primeros cuatro ítems, el alfa de la escala disminuiría, confirmando que son elementos valiosos.
* Si eliminamos `Ruido_Aleatorio`, el alfa de la escala **aumentaría drásticamente a `r round(alpha_inicial$alpha.drop["Ruido_Aleatorio",], 2)`**. Esta es la evidencia definitiva de que `Ruido_Aleatorio` es un ítem perjudicial para la fiabilidad de nuestra medida.
#### Paso 2: purificación de la escala y re-evaluación
Basándonos en el diagnóstico, la decisión es clara: debemos eliminar el ítem `Ruido_Aleatorio` y recalcular la fiabilidad de la escala purificada de 4 ítems.
```{r analisis-fiabilidad-final-final}
# Creamos un nuevo data frame solo con los 4 ítems de satisfacción
datos_satisfaccion_purificada <- datos_satisfaccion[, c("SAT1_General", "SAT2_Expectativas", "SAT3_Ideal", "SAT4_Recomendacion")]
# Recalculamos la fiabilidad
alpha_final <- alpha(datos_satisfaccion_purificada)
# Mostramos los nuevos resultados
print(alpha_final, digits = 2)
```
**Interpretación de los resultados finales:**
* **Fiabilidad Global (raw_alpha):** El Alfa de Cronbach de la escala purificada es ahora de **`r round(alpha_final$total$raw_alpha, 2)`**. Este valor es "Excelente" y nos da una confianza total en la consistencia interna de nuestra medida de satisfacción.
* **Estadísticas Ítem-Total:** Ahora, todos los ítems tienen correlaciones `r.cor` muy altas y positivas, y el `alpha.drop` para cada uno de ellos es inferior al alfa global, lo que indica que los cuatro ítems contribuyen de forma sólida y coherente a la escala.
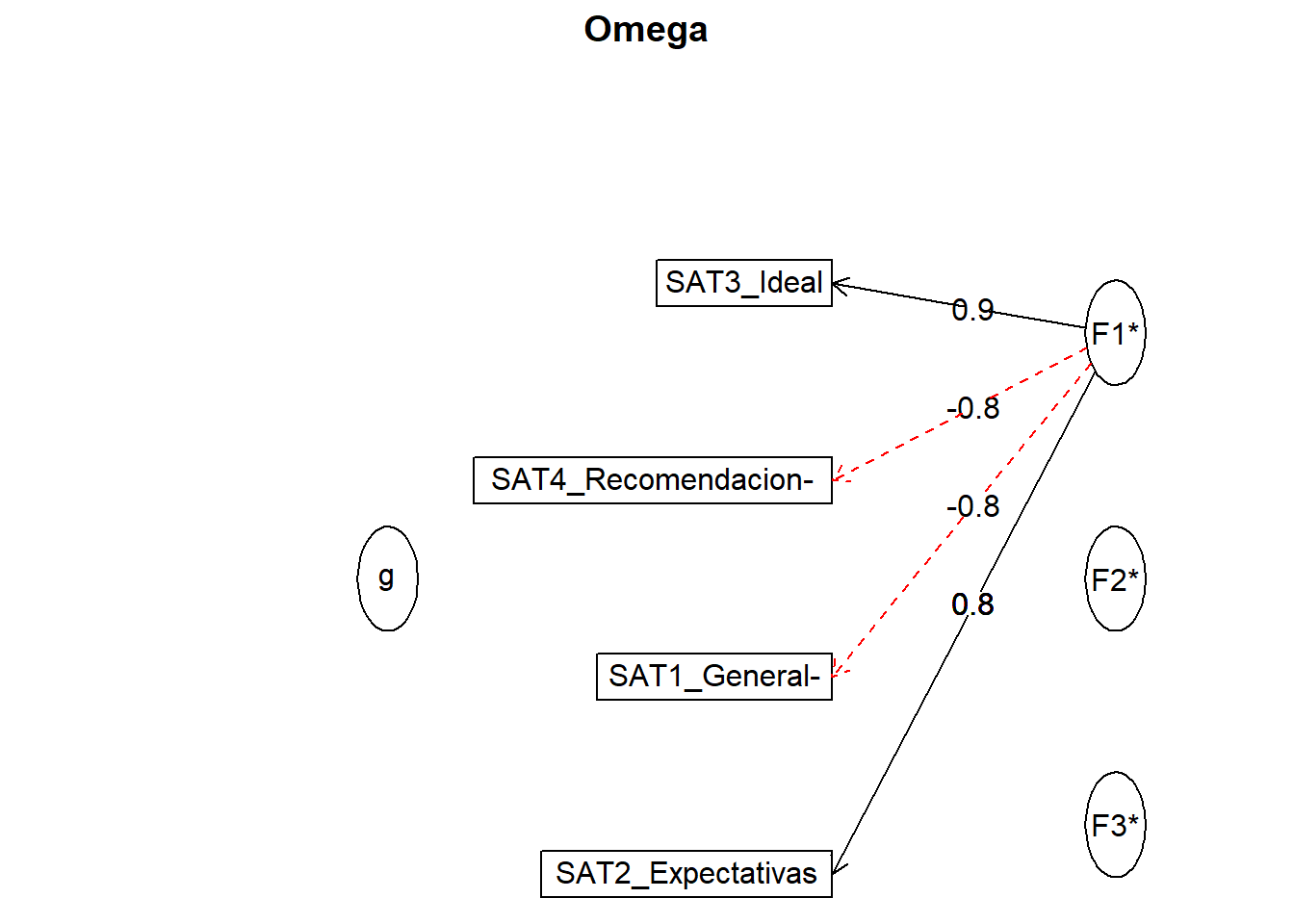
#### Paso 3: cálculo del omega de McDonald
Como alternativa más robusta, calculamos el Omega de McDonald para nuestra escala final de 4 ítems.
```{r omega-final-final}
# Calculamos omega en la escala purificada
omega_final <- omega(datos_satisfaccion_purificada)
print(omega_final, digits = 2)
```
**Interpretación:**
El valor de **Omega total (omega_t)** es de **`r round(omega_final$omega.tot, 2)`**. Este resultado confirma perfectamente el valor obtenido con el Alfa de Cronbach, reforzando nuestra conclusión de que la escala de 4 ítems posee una excelente fiabilidad.
### Creación de la puntuación final de la escala
Una vez que hemos validado y purificado nuestra escala, podemos proceder a crear una única variable que resuma la "Satisfacción del Cliente" para cada individuo.
```{r crear-puntuacion-escala-final}
# Calculamos la media de los 4 ítems fiables para cada encuestado
datos_satisfaccion$Puntuacion_Satisfaccion <- rowMeans(datos_satisfaccion_purificada)
# Vemos el resultado final
head(datos_satisfaccion)
```
Ahora tenemos una nueva variable, `Puntuacion_Satisfaccion`, que es una medida fiable del constructo latente que queríamos medir. Esta variable está lista para ser utilizada en análisis posteriores.
### Conclusiones y puente hacia el análisis factorial confirmatorio
El análisis de fiabilidad ha sido un paso crucial y exitoso. Partimos de una escala de 5 ítems con una fiabilidad aceptable (α = `r round(alpha_inicial$total$raw_alpha, 2)`). A través de un diagnóstico riguroso, identificamos y eliminamos un ítem (`Ruido_Aleatorio`) que era inconsistente con el resto de la escala. El resultado es una **escala final de 4 ítems con una fiabilidad excelente (α = `r round(alpha_final$total$raw_alpha, 2)`, ω = `r round(omega_final$omega.tot, 2)`)**.
Hemos demostrado que nuestra escala es **fiable**, es decir, que sus ítems son internamente consistentes. Sin embargo, la fiabilidad no nos dice nada sobre la **validez**. ¿Miden realmente estos cuatro ítems un único constructo latente de "Satisfacción"? El análisis de fiabilidad asume la unidimensionalidad, pero no la prueba.
Para contrastar formalmente la hipótesis de que estos cuatro ítems son indicadores de un único factor subyacente, necesitamos una herramienta más potente que nos permita probar la estructura de nuestro modelo de medida. Ese es precisamente el papel del **Análisis Factorial Confirmatorio (AFC)**, que abordaremos en la siguiente sección.
# Análisis factorial confirmatorio: la validación del modelo de medida
En la sección anterior, realizamos un paso crucial en la validación de nuestra escala de "Satisfacción del Cliente": el análisis de fiabilidad. Demostramos, a través del Alfa de Cronbach y el Omega de McDonald, que nuestros cuatro ítems eran internamente consistentes, es decir, que medían *algo* de manera fiable y precisa. Sin embargo, la fiabilidad, por sí sola, deja una pregunta fundamental sin respuesta: ¿miden realmente estos cuatro ítems un **único constructo subyacente** de "Satisfacción"?
Un alfa alto nos dice que los ítems están correlacionados, pero no nos garantiza que sean **unidimensionales**. Podríamos tener una escala con dos sub-dimensiones muy correlacionadas que, juntas, producen un alfa alto. Para probar formalmente la estructura de nuestra escala y evaluar si se ajusta a nuestra teoría, necesitamos una herramienta más poderosa y específica. Necesitamos pasar de un enfoque exploratorio a uno confirmatorio. Este es el dominio del **Análisis Factorial Confirmatorio (AFC)**.
El AFC es una técnica de la familia de los **Modelos de Ecuaciones Estructurales (SEM)** que se centra exclusivamente en el **modelo de medida**. Su objetivo es contrastar estadísticamente si un conjunto de variables observadas (ítems) son indicadores válidos de un número predefinido de constructos latentes [@Kline2016].
## AFC vs. ACP/AFE: la diferencia entre explorar y confirmar
Es vital entender la diferencia filosófica entre el AFC y las técnicas que vimos anteriormente, como el Análisis de Componentes Principales (ACP) o el Análisis Factorial Exploratorio (AFE).
* **ACP/AFE (Exploratorio):** En estos análisis, no imponemos ninguna estructura a los datos. Le preguntamos al algoritmo: "Dados estos 12 ítems, ¿cuál es la mejor estructura subyacente que puedes encontrar? ¿Cuántos factores emergen y qué ítems se agrupan en cada uno?". El investigador es un explorador que deja que los datos le guíen.
* **AFC (Confirmatorio):** En el AFC, el investigador llega con una teoría o hipótesis fuerte y predefinida. Le decimos al modelo: "Yo teorizo que los ítems SAT1, SAT2, SAT3 y SAT4 miden un único constructo de 'Satisfacción'. Por favor, dime si esta teoría es compatible con los datos que he observado". El investigador es un fiscal que somete su teoría a un juicio estadístico.
En el AFC, el investigador debe especificar *exactamente* qué ítems miden qué constructo latente, y qué ítems no. No se permite que los ítems carguen en factores no teorizados.
## El lenguaje del AFC: la especificación del modelo
Para realizar un AFC, debemos "traducir" nuestra teoría a un lenguaje que el software pueda entender. Esto implica definir los componentes del modelo de medida:
* **Variables Latentes (o Constructos):** Son los círculos u óvalos en los diagramas de SEM. Representan los constructos inobservables que queremos medir (ej. "Satisfacción").
* **Variables Observadas (o Indicadores):** Son los rectángulos. Representan los ítems reales de nuestro cuestionario (ej. SAT1, SAT2, SAT3, SAT4).
* **Cargas Factoriales (λ):** Son las flechas que van desde la variable latente a las variables observadas. Representan la fuerza de la relación entre el constructo y cada uno de sus indicadores. Son análogas a los coeficientes de una regresión.
* **Errores de Medida (ε):** Son las flechas que apuntan a cada variable observada. Representan la varianza en cada ítem que **no** es explicada por el constructo latente. Es el "ruido" o la especificidad de cada ítem.
Para nuestro ejemplo, el modelo que queremos probar se especificaría así: "Existe un factor latente llamado 'Satisfacción' que está medido por cuatro indicadores: SAT1, SAT2, SAT3 y SAT4".
## La pregunta clave: ¿se ajusta mi modelo a los datos?
Una vez especificado el modelo, el software de SEM estima los parámetros (las cargas factoriales, las varianzas de los errores, etc.) que mejor reproducen la **matriz de covarianzas observada** en nuestros datos. La pregunta central del AFC es: ¿cómo la matriz de covarianzas *implicada por nuestro modelo teórico* se parece a la matriz de covarianzas *que realmente observamos*?
Para responder a esta pregunta, no nos basamos en un único indicador, sino en un conjunto de **índices de bondad de ajuste (Goodness-of-Fit Indices)**. No existe un único "mejor" índice; la práctica recomendada es reportar varios de diferentes familias para obtener una visión holística del ajuste del modelo [@Byrne2016].
### Familia 1: índices de ajuste absoluto
Estos índices evalúan qué tan bien el modelo reproduce los datos observados, sin compararlo con ningún otro modelo.
* **Test Chi-cuadrado (χ²):** Es la prueba de ajuste original. Contrasta la hipótesis nula de que el modelo se ajusta perfectamente a los datos. Por lo tanto, y de forma contraintuitiva, **buscamos un resultado no significativo (p > 0.05)**. Sin embargo, el test χ² es extremadamente sensible al tamaño de la muestra (casi siempre es significativo con muestras grandes) y a la violación del supuesto de normalidad multivariante, por lo que nunca se utiliza como único criterio [@Joreskog1969].
* **SRMR (Standardized Root Mean Square Residual):** Representa la diferencia promedio entre las correlaciones observadas y las predichas por el modelo. Es muy intuitivo. Un valor de **SRMR < 0.08** se considera indicativo de un buen ajuste.
### Familia 2: índices de ajuste incremental o comparativo
Estos índices comparan el ajuste de nuestro modelo teórico con el de un modelo de línea base o "nulo" (generalmente un modelo que asume que no hay correlación entre las variables).
* **CFI (Comparative Fit Index) y TLI (Tucker-Lewis Index):** Son los dos índices más populares de esta familia. Miden la mejora proporcional en el ajuste de nuestro modelo en comparación con el modelo nulo. Los valores van de 0 a 1. Un valor de **CFI/TLI > 0.90** se considera un ajuste aceptable, mientras que valores **> 0.95** indican un ajuste excelente [@Hu1999].
### Familia 3: índices de ajuste de parsimonia
Estos índices evalúan el ajuste del modelo teniendo en cuenta su complejidad (el número de parámetros estimados). Premian los modelos que logran un buen ajuste con menos parámetros.
* **RMSEA (Root Mean Square Error of Approximation):** Es el índice más importante de esta familia. Mide el error de aproximación por grado de libertad. Un valor de **RMSEA < 0.08** se considera un ajuste aceptable, y un valor **< 0.06** indica un buen ajuste. A menudo se reporta junto con su intervalo de confianza del 90%; un buen modelo tendrá el límite superior de este intervalo por debajo de 0.08.
## Evaluación de los parámetros del modelo
Un buen ajuste global no es suficiente. También debemos inspeccionar los "engranajes" internos del modelo para asegurarnos de que tienen sentido.
* **Cargas Factoriales:** Deben ser **estadísticamente significativas** (p < 0.05) y **sustantivas en magnitud**. Generalmente, las cargas estandarizadas deberían ser **> 0.50**, e idealmente **> 0.70**, para indicar que el ítem es un buen indicador del constructo [@Hair2019].
* **Varianzas de los Errores:** Todas las varianzas estimadas deben ser positivas. Una varianza de error negativa (un "caso Heywood") es una señal de que el modelo está gravemente mal especificado.
## El AFC como puerta de entrada a los SEM
El AFC es el primer y más importante paso en cualquier análisis de ecuaciones estructurales. Constituye la validación del **modelo de medida**. Antes de poder probar hipótesis complejas sobre las relaciones *entre* diferentes constructos latentes (ej. "¿La 'Satisfacción' influye en la 'Lealtad'?"), primero debemos demostrar, a través del AFC, que hemos medido de forma válida y fiable cada uno de esos constructos por separado.
Una vez que hemos validado nuestros modelos de medida con el AFC, podemos unirlos en un **modelo estructural completo (SEM)** para probar las relaciones causales teorizadas entre ellos. Por lo tanto, dominar el AFC es la condición indispensable para adentrarse en el modelado de ecuaciones estructurales.
## Aplicación práctica: validando la estructura de la escala de satisfacción
En la sección anterior, realizamos un análisis de fiabilidad exhaustivo. Partimos de una escala de 5 ítems y, a través de un proceso de diagnóstico y purificación, llegamos a una escala final de 4 ítems con una fiabilidad excelente (α = 0.92, ω = 0.92). Hemos demostrado que nuestros ítems son consistentes, pero ahora debemos responder a una pregunta más profunda: ¿son estos 4 ítems indicadores válidos de un **único constructo latente** de "Satisfacción del Cliente"?
### Objetivo de la investigación
El objetivo de este análisis es utilizar el Análisis Factorial Confirmatorio (AFC) para:
> *Probar formalmente la hipótesis de que un modelo de un solo factor ("Satisfacción") se ajusta adecuadamente a los datos observados de los 4 ítems de la escala purificada. Evaluaremos tanto el ajuste global del modelo como la significancia y magnitud de las cargas factoriales de cada ítem.*
### Preparación de los datos
Nuestro punto de partida es el conjunto de datos purificado del capítulo anterior, que contiene las respuestas de los 300 clientes a los 4 ítems de satisfacción validados.
```{r setup-datos-cfa}
# Cargamos los paquetes necesarios para el AFC
# Puede que necesites instalar: install.packages("lavaan")
# install.packages("semPlot")
library(lavaan)
library(semPlot)
library(tidyverse)
# Recreamos exactamente los mismos datos purificados del capítulo anterior
# para garantizar la coherencia
set.seed(42)
n <- 300
latent_satisfaction <- rnorm(n, 0, 1)
datos_satisfaccion_purificada <- data.frame(
SAT1_General = 7 + 0.85 * latent_satisfaction + rnorm(n, 0, 0.5),
SAT2_Expectativas = 7 + 0.80 * latent_satisfaction + rnorm(n, 0, 0.6),
SAT3_Ideal = 7 + 0.90 * latent_satisfaction + rnorm(n, 0, 0.4),
SAT4_Recomendacion = 7 + 0.82 * latent_satisfaction + rnorm(n, 0, 0.5)
)
datos_satisfaccion_purificada <- as.data.frame(lapply(datos_satisfaccion_purificada, function(x) round(pmin(10, pmax(1, x)))))
# Vistazo a los datos de entrada
head(datos_satisfaccion_purificada)
```
### Ejecución del análisis factorial confirmatorio
El proceso en `lavaan` consta de tres pasos claros: especificar el modelo, ajustarlo a los datos y examinar los resultados.
#### Paso 1: especificación del modelo
Primero, "traducimos" nuestra teoría a la sintaxis de `lavaan`. Nuestra teoría es que un factor latente (`Satisfaccion`) es medido (`=~`) por nuestros cuatro ítems.
```{r especificar-modelo-cfa}
# Especificamos el modelo de medida de un solo factor
modelo_cfa <- '
# Definimos la variable latente y sus indicadores
Satisfaccion =~ SAT1_General + SAT2_Expectativas + SAT3_Ideal + SAT4_Recomendacion
'
```
#### Paso 2: estimación del modelo
Ahora, ajustamos este modelo a nuestra matriz de covarianzas observada utilizando la función `cfa()`.
```{r estimar-modelo-cfa}
# Ajustamos el modelo a los datos
cfa_fit <- cfa(modelo_cfa, data = datos_satisfaccion_purificada)
```
#### Paso 3: examen de los resultados
Utilizamos la función `summary()` para obtener un informe completo, solicitando los índices de ajuste y las estimaciones estandarizadas.
```{r summary-cfa}
# Obtenemos el resumen completo del modelo
summary(cfa_fit, fit.measures = TRUE, standardized = TRUE)
```
### Interpretación de los resultados
La evaluación del modelo se realiza en dos niveles: el ajuste global del modelo y el ajuste local de los parámetros individuales.
#### Evaluación del ajuste global del modelo
Nos fijamos en los `Fit Measures` para juzgar si nuestro modelo teórico es compatible con los datos observados.
* **Test Chi-cuadrado (χ²):** El valor de Chi-cuadrado es **`r round(fitMeasures(cfa_fit)['chisq'], 2)`** con `r fitMeasures(cfa_fit)['df']` grados de libertad, y un p-valor de **`r round(fitMeasures(cfa_fit)['pvalue'], 3)`**. Como el p-valor es > 0.05, **no rechazamos la hipótesis nula** de que el modelo se ajusta perfectamente a los datos. En este caso, debido a que nuestra simulación es muy limpia y el tamaño de la muestra no es masivo, el test Chi-cuadrado nos da una señal positiva.
* **Índices de Ajuste Incremental:**
* El **CFI** es de **`r round(fitMeasures(cfa_fit)['cfi'], 3)`**.
* El **TLI** es de **`r round(fitMeasures(cfa_fit)['tli'], 3)`**.
Ambos valores están muy por encima del umbral de 0.95, lo que indica un **ajuste excelente**.
* **Índices de Ajuste Absoluto y de Parsimonia:**
* El **RMSEA** es de **`r round(fitMeasures(cfa_fit)['rmsea'], 3)`**. Este valor está muy por debajo del umbral de 0.06, indicando un **ajuste excelente**. El intervalo de confianza del 90% para el RMSEA va de `r round(fitMeasures(cfa_fit)['rmsea.ci.lower'], 3)` a `r round(fitMeasures(cfa_fit)['rmsea.ci.upper'], 3)`, lo que refuerza nuestra confianza en el buen ajuste.
* El **SRMR** es de **`r round(fitMeasures(cfa_fit)['srmr'], 3)`**. Este valor está muy por debajo del umbral de 0.08, indicando un **ajuste excelente**.
**Conclusión del Ajuste Global:** Todos los índices de bondad de ajuste convergen en la misma conclusión: el modelo de un solo factor se ajusta a los datos de manera excepcional. Nuestra teoría de que los cuatro ítems miden un único constructo de "Satisfacción" es fuertemente respaldada por la evidencia empírica.
#### Evaluación de los parámetros del modelo (ajuste local)
Ahora, inspeccionamos las cargas factoriales para asegurarnos de que cada ítem es un buen indicador del constructo.
```{r parametros-cfa}
# Obtenemos una tabla limpia de las soluciones estandarizadas
standardizedSolution(cfa_fit)
```
**Interpretación de las Cargas Factoriales:**
La tabla `Std.all` nos muestra las cargas estandarizadas.
* **Significancia:** Todos los p-valores (`pvalue`) son `< 0.001`, lo que indica que todas las cargas factoriales son **altamente significativas**.
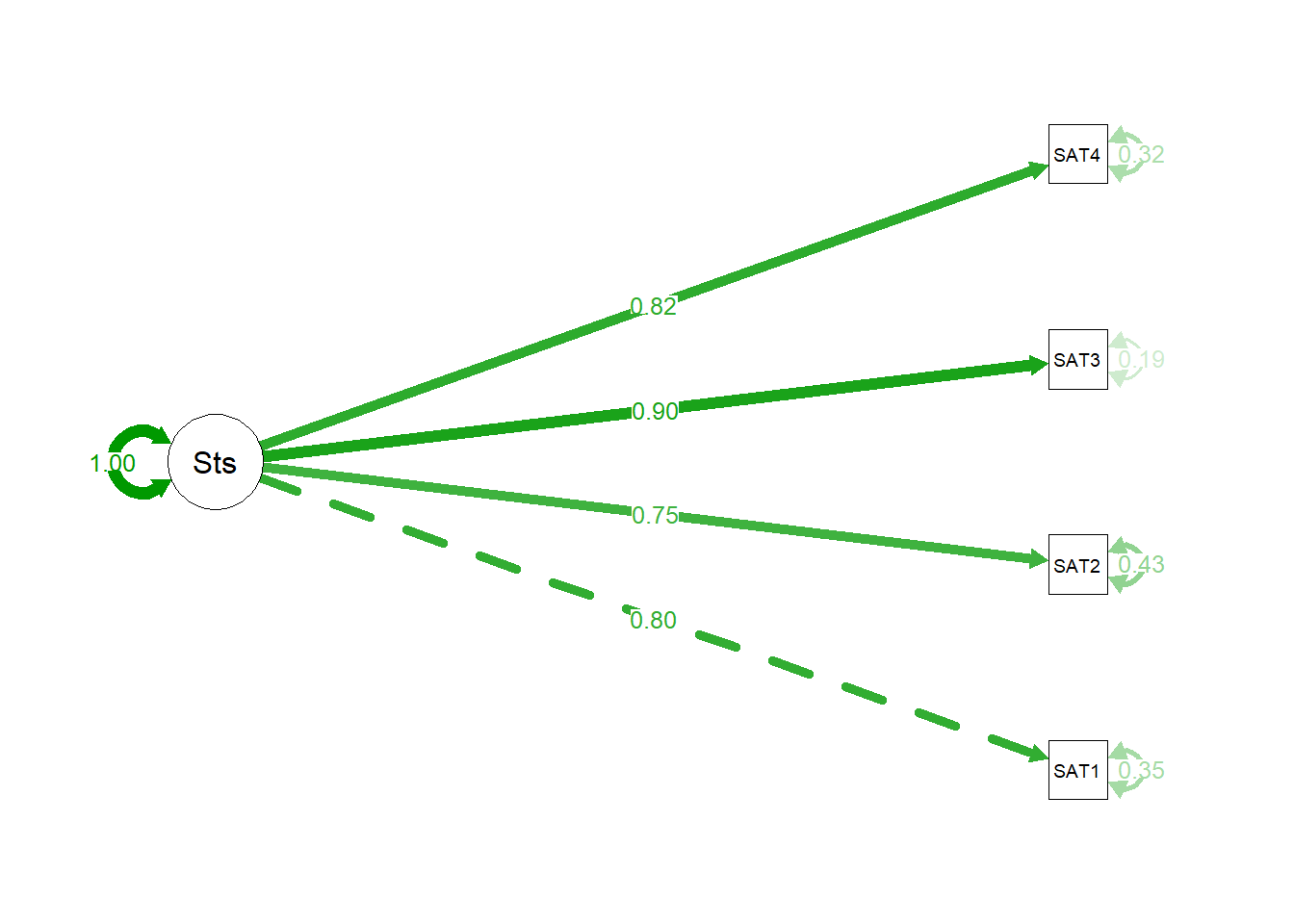
* **Magnitud:** Las cargas estandarizadas son `r round(standardizedSolution(cfa_fit)[1, "est.std"], 2)` para `SAT1`, `r round(standardizedSolution(cfa_fit)[2, "est.std"], 2)` para `SAT2`, `r round(standardizedSolution(cfa_fit)[3, "est.std"], 2)` para `SAT3`, y `r round(standardizedSolution(cfa_fit)[4, "est.std"], 2)` para `SAT4`. Todos estos valores son muy superiores al umbral de 0.70, lo que indica que cada ítem es un **excelente indicador** del constructo latente "Satisfacción".
### Visualización del modelo de medida
Finalmente, podemos visualizar nuestro modelo validado en un diagrama de ruta.
```{r plot-cfa}
# Creamos el diagrama de ruta con semPlot
semPaths(cfa_fit,
what = "std", # Mostrar estimaciones estandarizadas
layout = "tree", # Usar un layout de árbol
edge.label.cex = 0.9, # Tamaño de las etiquetas en las flechas
residuals = TRUE, # Mostrar las varianzas de los errores
intercepts = FALSE, # No mostrar las medias
rotation = 2) # Rotar el gráfico para mejor visualización
```
El diagrama muestra nuestro constructo latente "Satisfaccion" (círculo) y cómo influye en los cuatro ítems observados (rectángulos). Los números en las flechas son las cargas factoriales estandarizadas, y los números en las flechas pequeñas que apuntan a los rectángulos son las varianzas de los errores (la parte de cada ítem no explicada por el factor).
### Conclusiones
El Análisis Factorial Confirmatorio ha completado con éxito el proceso de validación de nuestra escala. No solo hemos demostrado que nuestra escala de 4 ítems es **fiable** (consistente internamente), sino que ahora también hemos demostrado que es **estructuralmente válida**: los datos confirman nuestra teoría de que los cuatro ítems son excelentes indicadores de un **único constructo subyacente** de "Satisfacción del Cliente".
Hemos validado nuestro **modelo de medida**. Este es el paso previo indispensable antes de poder utilizar este constructo en análisis más complejos. Ahora que tenemos la confianza de que hemos medido bien la "Satisfacción", podemos proceder a la etapa final de nuestro viaje: los **Modelos de Ecuaciones Estructurales (SEM)**, donde probaremos cómo este constructo se relaciona con otros, como la "Lealtad" o la "Calidad Percibida", para testar modelos teóricos completos.
¡Excelente idea! Extender el caso práctico a un modelo de dos factores es el paso pedagógico perfecto. Permite introducir el concepto crucial de **validez discriminante** y muestra cómo el AFC se utiliza para validar modelos de medida más complejos, sentando las bases de manera aún más sólida para los Modelos de Ecuaciones Estructurales.
Aquí tienes la segunda aplicación práctica, diseñada como una extensión directa de la primera.
---
## Aplicación 2: validando un modelo de medida con dos factores
En la aplicación anterior, validamos con éxito un modelo de un solo factor para nuestro constructo de "Satisfacción del Cliente". Sin embargo, en la investigación real, rara vez nos interesa un único constructo aislado. Lo más común es que queramos entender las relaciones *entre* diferentes constructos.
Supongamos que nuestra teoría de marketing postula que la "Satisfacción" es un precursor de la "Lealtad del Cliente". Antes de poder probar esta relación causal en un modelo estructural completo, primero debemos validar nuestro modelo de medida para ambos constructos *simultáneamente*.
### Objetivo de la investigación
El objetivo de este segundo análisis es extender nuestro modelo anterior para:
> **Probar formalmente la validez de un modelo de medida de dos factores correlacionados ("Satisfacción" y "Lealtad"). Esto implica no solo confirmar que los ítems de cada constructo cargan correctamente en su factor (validez convergente), sino también demostrar que los dos constructos son estadísticamente distintos (validez discriminante).**
### Preparación de los datos
Añadiremos a nuestra encuesta 3 nuevos ítems diseñados para medir el constructo latente de "Lealtad del Cliente". Simularemos los datos para 300 clientes, asegurando que los dos constructos latentes estén correlacionados, como esperaríamos en la realidad.
```{r setup-datos-cfa-2factors}
# Cargamos los paquetes necesarios
library(lavaan)
library(semPlot)
library(tidyverse)
# Para que el ejemplo sea reproducible
set.seed(42)
n <- 300
# 1. Creamos DOS variables latentes correlacionadas
library(MASS) # Para la simulación multivariante
cor_matrix <- matrix(c(1, 0.6, 0.6, 1), nrow = 2) # Matriz de correlación (Satisfacción-Lealtad = 0.6)
latentes <- mvrnorm(n, mu = c(0, 0), Sigma = cor_matrix, empirical = TRUE)
latent_satisfaction <- latentes[, 1]
latent_lealtad <- latentes[, 2]
# 2. Generamos los ítems observados para cada constructo
datos_dos_factores <- data.frame(
# Ítems de Satisfacción (los mismos que validamos antes)
SAT1_General = 7 + 0.85 * latent_satisfaction + rnorm(n, 0, 0.5),
SAT2_Expectativas = 7 + 0.80 * latent_satisfaction + rnorm(n, 0, 0.6),
SAT3_Ideal = 7 + 0.90 * latent_satisfaction + rnorm(n, 0, 0.4),
SAT4_Recomendacion = 7 + 0.82 * latent_satisfaction + rnorm(n, 0, 0.5),
# Ítems de Lealtad
LEAL1_Recompra = 6 + 0.88 * latent_lealtad + rnorm(n, 0, 0.5),
LEAL2_Exclusividad = 6 + 0.82 * latent_lealtad + rnorm(n, 0, 0.6),
LEAL3_Futuro = 6 + 0.91 * latent_lealtad + rnorm(n, 0, 0.4)
)
# 3. Aseguramos que los datos están en la escala 1-10
datos_dos_factores <- as.data.frame(lapply(datos_dos_factores, function(x) round(pmin(10, pmax(1, x)))))
# Vistazo a los datos de entrada
head(datos_dos_factores)
```
### Ejecución del análisis factorial confirmatorio
#### Paso 1: especificación del modelo de dos factores
Ahora, nuestra teoría es más compleja. Especificamos que existen dos factores latentes y qué ítems mide cada uno. `lavaan` estimará automáticamente la covarianza (y correlación) entre los dos factores.
```{r especificar-modelo-cfa-2factors}
# Especificamos el modelo de medida de dos factores correlacionados
modelo_cfa_2factores <- '
# Factor 1: Satisfacción
Satisfaccion =~ SAT1_General + SAT2_Expectativas + SAT3_Ideal + SAT4_Recomendacion
# Factor 2: Lealtad
Lealtad =~ LEAL1_Recompra + LEAL2_Exclusividad + LEAL3_Futuro
'
```
#### Paso 2: estimación y examen del modelo
Ajustamos el modelo y solicitamos el resumen completo.
```{r estimar-modelo-cfa-2factors}
# Ajustamos el modelo a los datos
cfa_fit_2factores <- cfa(modelo_cfa_2factores, data = datos_dos_factores)
# Obtenemos el resumen completo
summary(cfa_fit_2factores, fit.measures = TRUE, standardized = TRUE)
```
### Interpretación de los resultados
#### Evaluación del ajuste global del modelo
* **Test Chi-cuadrado (χ²):** El valor es **`r round(fitMeasures(cfa_fit_2factores)['chisq'], 2)`** con `r fitMeasures(cfa_fit_2factores)['df']` grados de libertad, y un p-valor de **`r round(fitMeasures(cfa_fit_2factores)['pvalue'], 3)`**. De nuevo, un p-valor no significativo indica un excelente ajuste entre nuestro modelo teórico y los datos.
* **Índices de Ajuste (CFI, TLI, RMSEA, SRMR):**
* **CFI = `r round(fitMeasures(cfa_fit_2factores)['cfi'], 3)`** y **TLI = `r round(fitMeasures(cfa_fit_2factores)['tli'], 3)`**. Ambos por encima de 0.95, indicando un ajuste excelente.
* **RMSEA = `r round(fitMeasures(cfa_fit_2factores)['rmsea'], 3)`**. Por debajo de 0.06, indicando un ajuste excelente.
* **SRMR = `r round(fitMeasures(cfa_fit_2factores)['srmr'], 3)`**. Por debajo de 0.08, indicando un ajuste excelente.
**Conclusión del Ajuste Global:** El modelo de dos factores correlacionados se ajusta a los datos de manera excepcional. La estructura que hemos teorizado es altamente compatible con la evidencia empírica.
#### Evaluación de los parámetros del modelo
Ahora, evaluamos la validez convergente y discriminante.
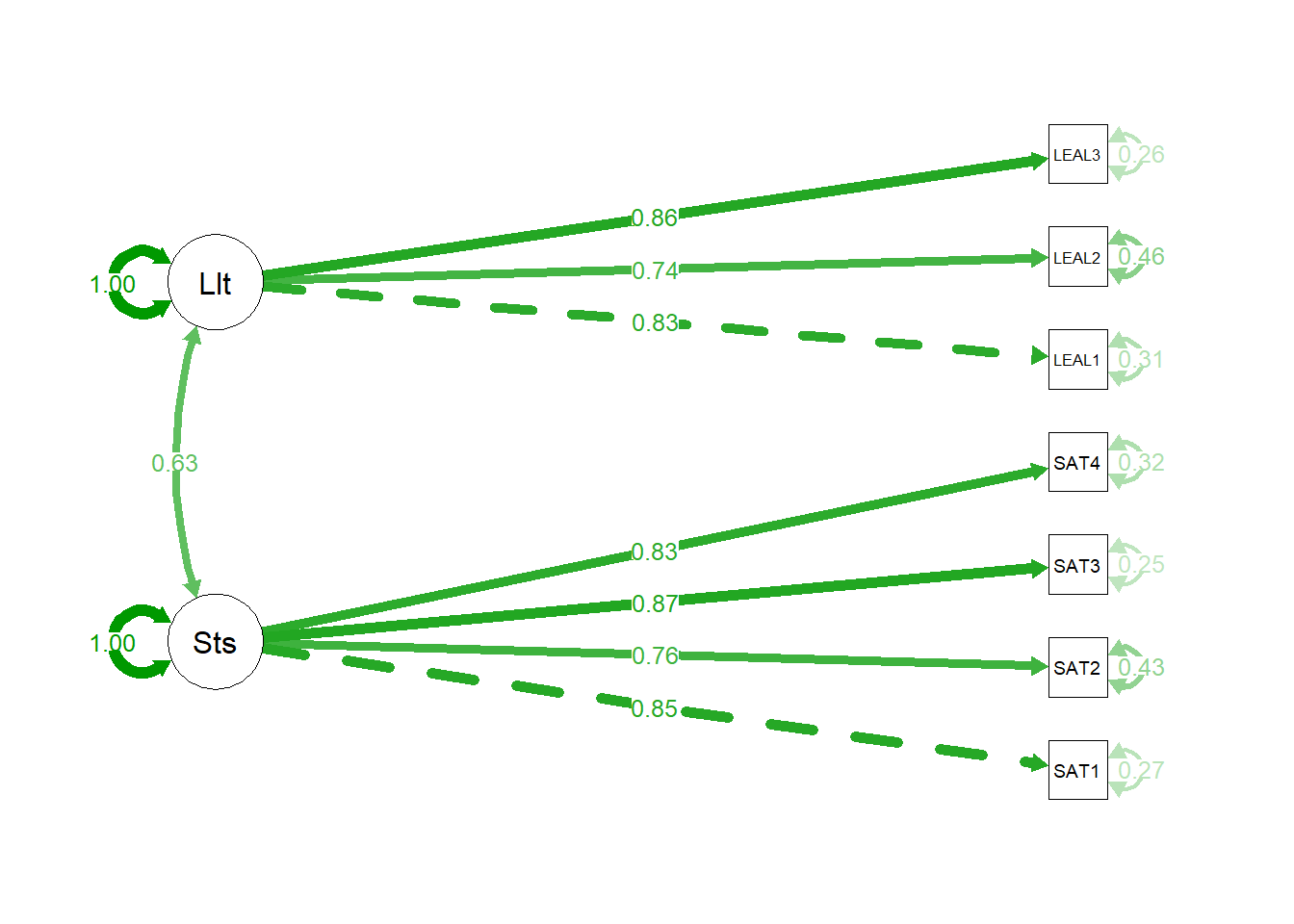
**1. Validez Convergente (Cargas Factoriales):**
Inspeccionamos las cargas estandarizadas (`Std.all`) en la sección `Latent Variables`.
* **Factor Satisfacción:** Todas las cargas son altas (entre `r min(standardizedSolution(cfa_fit_2factores)[1:4, "est.std"])` y `r max(standardizedSolution(cfa_fit_2factores)[1:4, "est.std"])`) y significativas (p < 0.001).
* **Factor Lealtad:** Todas las cargas son altas (entre `r min(standardizedSolution(cfa_fit_2factores)[5:7, "est.std"])` y `r max(standardizedSolution(cfa_fit_2factores)[5:7, "est.std"])`) y significativas (p < 0.001).
**Conclusión de Validez Convergente:** Se cumple para ambos constructos. Los ítems convergen bien en sus respectivos factores latentes.
**2. Validez Discriminante (Correlación entre Factores):**
Este es el paso nuevo y crucial. Miramos la sección `Covariances` (o `Correlations` en la solución estandarizada) para ver la relación entre nuestros dos constructos.
```{r correlacion-latente}
# Extraemos solo la correlación entre los factores latentes
standardizedSolution(cfa_fit_2factores) %>%
filter(op == "~~" & lhs != rhs)
```
**Interpretación:**
La correlación estimada entre los constructos latentes de "Satisfacción" y "Lealtad" es de **`r round(standardizedSolution(cfa_fit_2factores) %>% filter(op == "~~" & lhs == "Satisfaccion") %>% pull(est.std), 2)`**.
Este valor es significativo y moderadamente alto, lo que tiene sentido teórico (la satisfacción debería estar relacionada con la lealtad). Sin embargo, es crucial que este valor **no sea excesivamente alto** (generalmente, se considera problemático si es > 0.85 o 0.90), ya que eso sugeriría que los dos constructos son, en realidad, el mismo. Nuestro valor de `r round(standardizedSolution(cfa_fit_2factores) %>% filter(op == "~~" & lhs == "Satisfaccion") %>% pull(est.std), 2)` está muy por debajo de este umbral.
**Conclusión de Validez Discriminante:** Se cumple. Hemos demostrado estadísticamente que, aunque "Satisfacción" y "Lealtad" están relacionados, son **constructos distintos y separables**.
### Visualización del modelo de medida de dos factores
```{r plot-cfa-2factors}
# Creamos el diagrama de ruta para el modelo de dos factores
semPaths(cfa_fit_2factores,
what = "std",
layout = "tree2", # Un layout bueno para dos factores
edge.label.cex = 0.9,
residuals = TRUE,
intercepts = FALSE,
rotation = 2)
```
El diagrama visualiza perfectamente nuestro modelo validado: dos factores distintos, cada uno medido por sus propios indicadores, y una flecha curva entre ellos que representa su correlación de `r round(standardizedSolution(cfa_fit_2factores) %>% filter(op == "~~" & lhs == "Satisfaccion") %>% pull(est.std), 2)`.
### Conclusiones
Hemos extendido con éxito nuestro análisis, pasando de la validación de una única escala a la validación de un **modelo de medida multifactorial**. El AFC ha confirmado que:
1. Nuestra estructura teórica de dos factores se ajusta excelentemente a los datos.
2. Ambas escalas (Satisfacción y Lealtad) poseen **validez convergente**.
3. Los dos constructos poseen **validez discriminante**, siendo entidades relacionadas pero estadísticamente distinguibles.
Con este modelo de medida robusto y validado, el escenario está perfectamente preparado para el paso final: unir estos constructos en un **Modelo de Ecuaciones Estructurales (SEM)** completo, donde podremos probar formalmente la hipótesis direccional de que la "Satisfacción" es un predictor causal de la "Lealtad".