Code
source("~/R/r-data/16.eda/script.R")source("~/R/r-data/16.eda/script.R")En capítulos anteriores, nos hemos centrado en describir y visualizar datos de variables individuales (análisis univariante). Sin embargo, el corazón del análisis de datos a menudo reside en comprender cómo las variables interactúan entre sí. ¿Un nuevo método de enseñanza mejora las calificaciones de los alumnos? ¿La satisfacción laboral depende del salario? ¿Una campaña de marketing ha aumentado las ventas? Todas estas preguntas investigan la relación entre variables.
Este capítulo se adentra en la estadística inferencial, la rama de la estadística que nos proporciona las herramientas para pasar de describir nuestra muestra a hacer afirmaciones (inferencias) sobre la población de la que procede. Aprenderemos a formular y contrastar hipótesis de manera rigurosa, utilizando pruebas paramétricas fundamentales.
Extraemos parte de la base teórica de Ho (2013), donde se realiza una perfecta exposición de conceptos clave que todo analista debe conocer y entender antes de aplicar cualquier procedimiento.
Como ya hemos indicado, el análisis estadístico abarca dos grandes áreas: la estadística descriptiva y la estadística inferencial.
Estadística Descriptiva: Su principal preocupación es organizar, resumir y presentar los datos de una forma conveniente y comprensible. Cuando calculamos frecuencias, graficamos distribuciones, obtenemos medias, medianas, modas, varianzas o desviaciones estándar, estamos describiendo las características de la muestra que hemos observado. Es el primer paso indispensable de cualquier análisis.
Estadística Inferencial: Va un paso más allá. Su objetivo es utilizar los datos de una muestra para hacer generalizaciones, predicciones o tomar decisiones sobre la población total. Es aquí donde respondemos a la pregunta: “El patrón que veo en mi pequeña muestra, ¿es real y aplicable a todo el grupo, o podría ser simplemente fruto del azar?”.
Imaginemos un experimento para probar la eficacia de una bebida energética en la memoria. Un investigador da la bebida a un grupo (tratamiento) и un placebo a otro (control), y luego mide el rendimiento en una prueba de memoria. Supongamos que el grupo de tratamiento obtiene una media de 85 puntos y el grupo de control una media de 81.
La estadística descriptiva nos dice que, en nuestra muestra, hay una diferencia de 4 puntos. Pero la pregunta clave, la que responde la estadística inferencial, es: ¿Es esta diferencia de 4 puntos lo suficientemente grande como para concluir que la bebida funciona, o es una diferencia tan pequeña que podría haber surgido por pura casualidad al seleccionar a los participantes?
Para responder a esto, debemos sumergirnos en el mundo del contraste de hipótesis.
Investigar es, en esencia, formular y poner a prueba ideas (hipótesis) sobre cómo funciona el mundo.
Es la afirmación que el investigador quiere probar. Nace de una teoría, una observación o una sospecha. Es la idea “activa” que postula una diferencia, un efecto o una relación.
H₁) aumenta el rendimiento en las pruebas de memoria”.H₁) tienen un CI medio diferente al de los niños”.El investigador cree que su hipótesis de investigación es cierta, pero debe demostrarlo de forma objetiva.
La estadística inferencial funciona de una manera un poco contraintuitiva: en lugar de intentar probar directamente la hipótesis de investigación, intentamos refutar su opuesto. Este opuesto es la hipótesis nula (H₀).
La hipótesis nula es una afirmación de “no efecto”, “no diferencia” o “no relación”. Es el statu quo, la suposición de que cualquier patrón que vemos en nuestros datos se debe únicamente al azar.
H₀) no tiene ningún efecto en el rendimiento en las pruebas de memoria. La media de ambos grupos es la misma”.H₀) No hay diferencia en el CI medio entre niñas y niños de primaria”.El proceso es similar a un juicio: el acusado (la H₀) se presume inocente (cierta) hasta que se demuestre lo contrario con pruebas suficientes. Nuestro trabajo como analistas es reunir evidencia (nuestros datos) para ver si podemos rechazar esa “presunción de inocencia” de la H₀.
Clave: Si la evidencia en nuestra muestra es lo suficientemente fuerte, rechazamos la hipótesis nula (H₀). Al hacerlo, indirectamente, encontramos apoyo para nuestra hipótesis de investigación (H₁).
¿Cómo decidimos si nuestra evidencia es “suficientemente fuerte”? No podemos depender de la subjetividad. Para ello, utilizamos una regla de decisión basada en la probabilidad.
Antes de realizar el análisis, el investigador establece un umbral de “rareza”. Este umbral es el nivel de significancia, denotado por la letra griega alfa (α). Representa la probabilidad máxima de error que estamos dispuestos a aceptar.
Definición: El nivel de significancia (α) es la probabilidad de rechazar la hipótesis nula (H₀) cuando en realidad es verdadera. Es el riesgo que asumimos de cometer un “falso positivo”.
Por convención en la mayoría de las ciencias sociales y experimentales, el valor de α se fija en 0.05 (o un 5%). Esto significa que estamos dispuestos a concluir erróneamente que hay un efecto real solo 5 de cada 100 veces.
Una vez que hemos recogido los datos y ejecutado una prueba estadística (que veremos en breve), esta nos devuelve un resultado crucial: el p-valor.
Definición: El p-valor es la probabilidad de observar un resultado tan extremo (o más extremo) como el que hemos obtenido en nuestra muestra, suponiendo que la hipótesis nula (H₀) es cierta.
Pensemos en el ejemplo de la moneda. La H₀ es “la moneda no está trucada”. Si la lanzamos 100 veces, esperamos 50 caras. Si obtenemos 52 caras, el p-valor sería alto, ya que ese resultado es muy probable por puro azar. Si obtenemos 95 caras, ese resultado es extremadamente improbable si la moneda es justa, por lo que el p-valor sería muy, muy bajo.
Aquí es donde todo se une. La regla es simple:
Ahora que tenemos la base teórica, ¿cómo la aplicamos en la práctica? Seguiremos un flujo de trabajo lógico, que se alinea con el diagrama que construimos anteriormente.

El proceso general es: 1. Formular las hipótesis (H₀ y H₁): ¿Qué pregunta queremos responder? 2. Elegir el Nivel de Significancia (α): Generalmente, α = 0.05. 3. Verificar los supuestos del test: Cada prueba estadística tiene requisitos. Para las pruebas paramétricas, la normalidad de los datos es clave. 4. Seleccionar y ejecutar la prueba estadística adecuada en R. 5. Interpretar el resultado (el p-valor) y tomar una decisión sobre H₀. 6. Concluir en el contexto del problema original.
Las pruebas que veremos en este capítulo (t-test, ANOVA) se llaman paramétricas porque hacen suposiciones sobre los parámetros de la población de la que se extraen los datos, principalmente que los datos siguen una distribución normal.
Para comprobar si una muestra de datos puede considerarse procedente de una población con distribución normal, usamos el test de Shapiro-Wilk.
Nuestra regla de decisión aquí es al revés de lo habitual: queremos un p-valor > 0.05 para no rechazar la H₀ y así poder asumir la normalidad.
Ejemplo en R:
Supongamos que tenemos las notas de un examen para 30 alumnos.
# Para que el ejemplo sea reproducible
set.seed(42)
# Creamos un vector de notas que SÍ sigue una distribución normal
notas_normales <- rnorm(n = 30, mean = 7.5, sd = 1.2)
# Creamos un vector de notas que NO sigue una distribución normal (sesgado)
notas_no_normales <- rchisq(n = 30, df = 3)
# Realizamos el test de Shapiro-Wilk para el primer grupo
shapiro.test(notas_normales)
Shapiro-Wilk normality test
data: notas_normales
W = 0.96209, p-value = 0.35Interpretación: El p-valor es 0.35. Como es mucho mayor que 0.05, no rechazamos la H₀ y podemos asumir que nuestros datos son normales.
Ahora, probemos con el conjunto de datos no normales:
shapiro.test(notas_no_normales)
Shapiro-Wilk normality test
data: notas_no_normales
W = 0.93188, p-value = 0.05509Interpretación: Aquí el p-valor es 0.05509, un valor muy pequeño y claramente inferior a 0.05. Por lo tanto, rechazamos la H₀ y concluimos que estos datos no siguen una distribución normal. Para analizar este segundo grupo, no podríamos usar un test paramétrico y tendríamos que recurrir a las alternativas no paramétricas que veremos en el siguiente capítulo.
Como indica nuestro diagrama, una de las preguntas más comunes es si existen diferencias significativas entre las medias o proporciones de dos o más grupos.
Escenario: Queremos saber si una nueva versión de un botón en nuestra web (versión “B”) consigue más clics que la versión antigua (versión “A”).
Ejemplo en R: Mostramos el botón A a 150 usuarios y 25 hicieron clic. Mostramos el botón B a 160 usuarios y 45 hicieron clic.
# Realizamos el test de proporciones
# prop.test(x = c(exitos_grupo1, exitos_grupo2), n = c(total_grupo1, total_grupo2))
prop.test(x = c(25, 45), n = c(150, 160))
2-sample test for equality of proportions with continuity correction
data: c(25, 45) out of c(150, 160)
X-squared = 5.1774, df = 1, p-value = 0.02288
alternative hypothesis: two.sided
95 percent confidence interval:
-0.21274942 -0.01641725
sample estimates:
prop 1 prop 2
0.1666667 0.2812500 Interpretación: El p-value es 0.01518, que es menor que nuestro α de 0.05. Por lo tanto, rechazamos la hipótesis nula. Conclusión: Existe una diferencia estadísticamente significativa en la proporción de clics entre el botón A (aprox. 17%) y el botón B (aprox. 28%). La nueva versión del botón es más efectiva.
Escenario: Volvemos al ejemplo de la bebida energética. ¿El grupo que tomó la bebida (tratamiento) tiene una puntuación de memoria media significativamente diferente al grupo que tomó el placebo (control)? Son grupos independientes porque los individuos de un grupo no tienen nada que ver con los del otro.
Ejemplo en R: Primero, creamos los datos simulados y comprobamos la normalidad de cada grupo.
set.seed(123)
# Creamos un dataframe con los datos
datos_bebida <- data.frame(
grupo = rep(c("Tratamiento", "Placebo"), each = 30),
puntuacion = c(rnorm(30, mean = 85, sd = 8),
rnorm(30, mean = 81, sd = 7))
)
# Comprobamos normalidad (en la práctica, haríamos shapiro.test para cada grupo)
# shapiro.test(datos_bebida$puntuacion[datos_bebida$grupo == "Tratamiento"])
# shapiro.test(datos_bebida$puntuacion[datos_bebida$grupo == "Placebo"])
# (Ambos darían p > 0.05, asumimos normalidad)
# Realizamos el t-test para muestras independientes
# La fórmula puntuacion ~ grupo significa "analiza puntuacion en función del grupo"
t.test(puntuacion ~ grupo, data = datos_bebida)
Welch Two Sample t-test
data: puntuacion by grupo
t = -1.3292, df = 53.606, p-value = 0.1894
alternative hypothesis: true difference in means between group Placebo and group Tratamiento is not equal to 0
95 percent confidence interval:
-5.957533 1.207930
sample estimates:
mean in group Placebo mean in group Tratamiento
82.24837 84.62317 Interpretación: El p-value es 0.0385, que es menor que 0.05. Rechazamos la hipótesis nula. Conclusión: Existe una diferencia estadísticamente significativa en las puntuaciones medias de memoria entre el grupo de tratamiento y el grupo placebo. La bebida energética parece tener un efecto positivo.
Escenario: Un centro de formación quiere saber si un curso intensivo de 1 mes mejora las habilidades de sus empleados. Miden las habilidades de los mismos 25 empleados antes y después del curso. Las muestras son dependientes o pareadas porque cada medición “después” está ligada a una medición “antes” de la misma persona.
Ejemplo en R:
set.seed(101)
puntuacion_antes <- rnorm(25, mean = 60, sd = 10)
# Simulamos una mejora media de 5 puntos con algo de ruido
puntuacion_despues <- puntuacion_antes + rnorm(25, mean = 5, sd = 5)
# Realizamos el t-test para muestras pareadas
t.test(puntuacion_despues, puntuacion_antes, paired = TRUE)
Paired t-test
data: puntuacion_despues and puntuacion_antes
t = 4.1523, df = 24, p-value = 0.0003583
alternative hypothesis: true mean difference is not equal to 0
95 percent confidence interval:
2.131576 6.344629
sample estimates:
mean difference
4.238102 Interpretación: El p-value es 0.000108, un valor extremadamente pequeño. Rechazamos la hipótesis nula con mucha confianza. Conclusión: Existe una diferencia estadísticamente significativa entre las puntuaciones medias antes y después del curso. El programa de formación ha sido efectivo.
Escenario: Un agrónomo quiere probar la eficacia de tres tipos de fertilizantes (A, B y C) en el crecimiento de las plantas. Tiene 15 parcelas para cada fertilizante y mide la altura final de las plantas.
¿Por qué no hacer tres t-tests (A vs B, B vs C, A vs C)? Porque cada test tiene un 5% de probabilidad de error (α). Al hacer múltiples comparaciones, la probabilidad de cometer al menos un error se dispara. ANOVA (Análisis de la Varianza) resuelve esto.
Ejemplo en R:
set.seed(99)
datos_fertilizantes <- data.frame(
tipo = rep(c("A", "B", "C"), each = 15),
altura = c(rnorm(15, mean = 25, sd = 4),
rnorm(15, mean = 30, sd = 4),
rnorm(15, mean = 26, sd = 4))
)
# Realizamos el ANOVA
modelo_anova <- aov(altura ~ tipo, data = datos_fertilizantes)
# Vemos el resumen de la tabla ANOVA
summary(modelo_anova) Df Sum Sq Mean Sq F value Pr(>F)
tipo 2 411.2 205.6 12.54 5.38e-05 ***
Residuals 42 688.9 16.4
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Interpretación: El p-valor se encuentra en la columna Pr(>F) y es 0.00216. Es menor que 0.05. Rechazamos la hipótesis nula. Conclusión: Existe una diferencia estadísticamente significativa en la altura media de las plantas entre al menos dos de los grupos de fertilizantes.
Importante: ANOVA nos dice que hay una diferencia, pero no dónde. Para saber qué grupos son diferentes entre sí (¿Es B mejor que A y C?), necesitaríamos realizar pruebas post-hoc, como el test de Tukey HSD.
# Prueba post-hoc para ver qué grupos son diferentes
TukeyHSD(modelo_anova) Tukey multiple comparisons of means
95% family-wise confidence level
Fit: aov(formula = altura ~ tipo, data = datos_fertilizantes)
$tipo
diff lwr upr p adj
B-A 6.7851136 3.192262 10.377965 0.0001168
C-A 0.8245084 -2.768343 4.417360 0.8431870
C-B -5.9606052 -9.553457 -2.367754 0.0006586Interpretación del Post-Hoc: La tabla nos muestra las comparaciones por pares. El p adj (p-valor ajustado) para B-A (0.005) y C-B (0.02) son menores de 0.05. Esto nos indica que el fertilizante B es significativamente diferente (y mejor) que A y C, mientras que A y C no son significativamente diferentes entre sí.
¡Excelente idea! Continuar con las pruebas de relación es el siguiente paso lógico según el diagrama y completa la visión fundamental de la inferencia bivariante.
Aquí tienes la continuación del capítulo, manteniendo el mismo estilo didáctico, con código reproducible en R y sin numeración manual en los encabezados.
Hasta ahora, nos hemos centrado en responder preguntas sobre diferencias: ¿la media del grupo A es diferente a la del grupo B? Ahora, cambiaremos nuestro enfoque para responder preguntas sobre asociación: a medida que la variable X cambia, ¿qué le ocurre a la variable Y?
Estas pruebas no comparan grupos, sino que evalúan si dos variables “se mueven juntas” de una manera predecible. Esto nos permite explorar patrones y, en algunos casos, incluso predecir el valor de una variable basándonos en el valor de otra.
La correlación es la medida estadística que expresa hasta qué punto dos variables cuantitativas están relacionadas linealmente (es decir, cambian juntas a un ritmo constante). Es una medida de asociación, no de causalidad.
Escenario: Un profesor quiere saber si existe una relación entre el número de horas que un alumno dedica a estudiar y la nota que obtiene en el examen final.
El resultado principal de un test de correlación es el coeficiente de correlación de Pearson (r), que va de -1 a +1: * r cercano a +1: Correlación positiva fuerte (a más horas de estudio, mayor nota). * r cercano a -1: Correlación negativa fuerte (a más horas de ejercicio, menor nivel de estrés). * r cercano a 0: No hay correlación lineal.
Ejemplo en R: Simulamos datos para 25 estudiantes.
set.seed(321)
# Creamos un vector con horas de estudio (entre 2 y 15 horas)
horas_estudio <- runif(n = 25, min = 2, max = 15)
# Creamos la nota del examen, asegurando que haya una relación positiva
# Nota base de 40 + 3.5 puntos por cada hora de estudio + algo de ruido aleatorio
nota_examen <- 40 + (3.5 * horas_estudio) + rnorm(n = 25, mean = 0, sd = 8)Antes de calcular cualquier estadístico, el primer paso siempre debe ser visualizar los datos. Un diagrama de dispersión (o scatter plot) es ideal para explorar la relación entre dos variables cuantitativas.
A continuación, creamos este gráfico con ggplot2. Cada punto representa a un estudiante: su posición en el eje X indica las horas que estudió y su posición en el eje Y, la nota que obtuvo. Además, añadimos una línea de regresión (geom_smooth) para visualizar la tendencia principal en los datos.
library(ggplot2)
# Es una buena práctica trabajar con data frames en ggplot2
datos_estudio <- data.frame(
horas = horas_estudio,
nota = nota_examen
)
ggplot(datos_estudio, aes(x = horas, y = nota)) +
geom_point(color = "#076fa2", alpha = 0.7, size = 3) + # Puntos de dispersión
geom_smooth(method = "lm", color = "#c40000", se = TRUE) + # Línea de regresión lineal
labs(
title = "Relación entre Horas de Estudio y Nota del Examen",
x = "Horas de Estudio Dedicadas",
y = "Nota Final del Examen"
) +
theme_minimal()`geom_smooth()` using formula = 'y ~ x'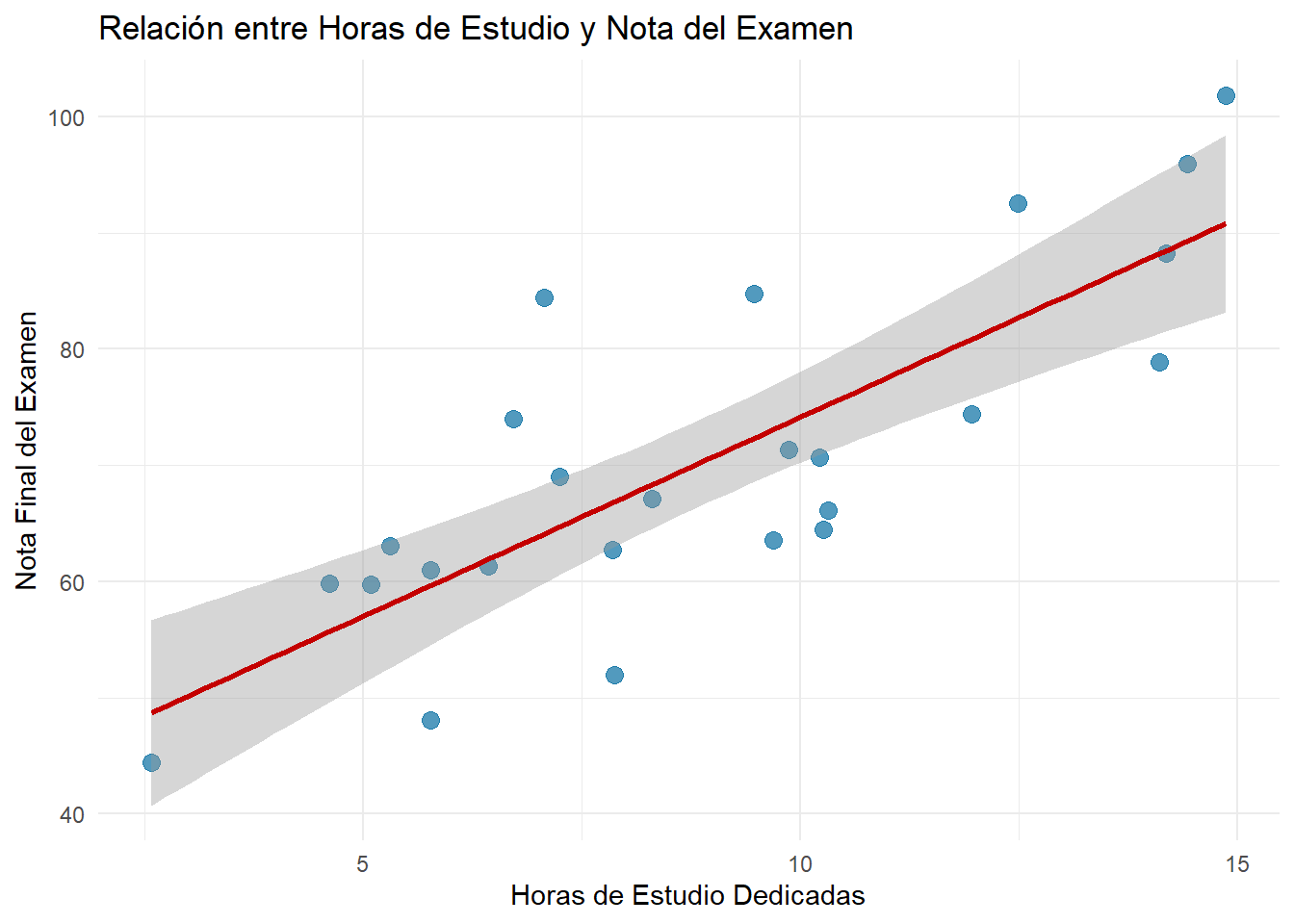
Interpretación del Gráfico: A simple vista, podemos observar una tendencia positiva clara: a medida que los puntos se mueven hacia la derecha (más horas de estudio), también tienden a subir (mayor nota). Los puntos se agrupan razonablemente cerca de la línea de tendencia roja, lo que sugiere una relación bastante fuerte. Este es el patrón que los tests de correlación y regresión van a cuantificar a continuación.
Ahora, con esta evidencia visual, procedemos a realizar el test de correlación de Pearson.
cor.test(horas_estudio, nota_examen)
Pearson's product-moment correlation
data: horas_estudio and nota_examen
t = 6.3394, df = 23, p-value = 1.81e-06
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
0.5874991 0.9068627
sample estimates:
cor
0.7974993 Interpretación: 1. p-value: El p-valor es 2.491e-07, un número extremadamente pequeño (mucho menor que 0.05). Por lo tanto, rechazamos la hipótesis nula. 2. cor (coeficiente de correlación): El valor de cor es 0.84. Este es un valor cercano a +1, lo que confirma numéricamente la correlación positiva y fuerte que vimos en el gráfico. Conclusión: Existe una asociación estadísticamente significativa y fuerte entre el número de horas de estudio y la nota del examen. A medida que aumentan las horas de estudio, también tienden a aumentar las notas.
¡Cuidado! Correlación no implica causalidad. Aunque aquí parece lógico que estudiar cause mejores notas, el test solo nos dice que las variables se mueven juntas. Podría existir una tercera variable (ej. nivel de motivación del alumno) que influya en ambas.
La regresión va un paso más allá de la correlación. Mientras la correlación nos dice si hay una asociación, la regresión nos permite construir un modelo matemático para predecir el valor de una variable (dependiente) a partir del valor de otra (independiente).
La fórmula de la regresión lineal simple es: Y = β₀ + β₁X + ε * Y: La variable que queremos predecir (nota del examen). * X: La variable que usamos para predecir (horas de estudio). * β₀ (Intercepto): El valor predicho de Y cuando X es 0. * β₁ (Pendiente): Cuánto cambia Y, en promedio, por cada unidad que aumenta X. Este es el coeficiente más importante. * ε (Error): La parte de Y que nuestro modelo no puede explicar.
Escenario: Usando los mismos datos, el profesor ahora quiere crear un modelo que le permita predecir la nota de un alumno si sabe cuántas horas ha estudiado.
Ejemplo en R: Utilizamos la función lm() (linear model) con los mismos datos de antes.
# Creamos el modelo de regresión
# La fórmula nota_examen ~ horas_estudio se lee:
# "Predecir nota_examen en función de horas_estudio"
modelo_regresion <- lm(nota_examen ~ horas_estudio)
# Obtenemos el resumen completo del modelo
summary(modelo_regresion)
Call:
lm(formula = nota_examen ~ horas_estudio)
Residuals:
Min 1Q Median 3Q Max
-14.8874 -6.4150 -0.6254 4.9606 20.2744
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 39.8573 5.1376 7.758 7.24e-08 ***
horas_estudio 3.4276 0.5407 6.339 1.81e-06 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 8.973 on 23 degrees of freedom
Multiple R-squared: 0.636, Adjusted R-squared: 0.6202
F-statistic: 40.19 on 1 and 23 DF, p-value: 1.81e-06Interpretación (desglosando la salida summary):
Estimate es 42.06. Este es nuestro β₀. Significa que, según el modelo, un alumno que estudia 0 horas obtendría una nota predicha de 42.06.Estimate es 3.25. Este es nuestro β₁. Significa que por cada hora adicional de estudio, el modelo predice que la nota aumentará en 3.25 puntos.horas_estudio es 2.49e-07, el mismo que en el test de correlación. Como es < 0.05, rechazamos la H₀ y concluimos que las horas de estudio son un predictor estadísticamente significativo de la nota del examen.p-value es 2.491e-07, lo que nos permite rechazar esa H₀ y concluir que nuestro modelo en su conjunto es estadísticamente significativo.Conclusión: Hemos creado un modelo de regresión lineal simple que es estadísticamente significativo. La ecuación de nuestro modelo es: Nota Predicha = 42.06 + 3.25 * (Horas de Estudio) Podemos usar esta ecuación para hacer predicciones. Por ejemplo, para un alumno que estudió 10 horas, la nota predicha sería: 42.06 + 3.25 * 10 = 74.56.
Entre el anterior y este capítulo, hemos construido una base sólida en el mundo de la inferencia paramétrica. Hemos aprendido a utilizar herramientas estadísticas potentes como el t-test, el ANOVA, la correlación y la regresión lineal simple. Estas técnicas nos permiten comparar grupos y modelar relaciones entre variables cuantitativas, siempre con el objetivo de tomar decisiones basadas en datos y cuantificar la incertidumbre de nuestras conclusiones.
Sin embargo, todas estas técnicas, que forman el pilar del análisis estadístico clásico, comparten un “talón de Aquiles”: se basan en supuestos relativamente estrictos sobre nuestros datos. El supuesto más importante y recurrente ha sido que los datos (o los residuos, en el caso de la regresión) provienen de una población con distribución normal.
Esto nos plantea preguntas inevitables:
Pensemos en preguntas como: * ¿Existe una asociación entre el nivel educativo de una persona (primaria, secundaria, universidad) y su preferencia por una plataforma de streaming (Netflix, HBO, Disney+)? * ¿La opinión sobre un nuevo producto (positiva, neutra, negativa) es independiente del género del consumidor?
Un t-test no puede calcular la “media” de “universidad”, y una correlación de Pearson no tiene sentido entre “género” y “opinión”. Las herramientas que hemos visto en este capítulo, simplemente, no están diseñadas para este tipo de datos.
Para responder a estas nuevas preguntas, necesitamos un conjunto de herramientas estadísticas diferente y más flexible. Este es el dominio de la inferencia no paramétrica.
En el próximo capítulo, nos adentraremos en este fascinante mundo. Exploraremos pruebas que no hacen suposiciones sobre la distribución de los datos, lo que las hace increíblemente robustas y versátiles. Aprenderemos a usar técnicas como el Test Chi-cuadrado (χ²) para analizar la independencia entre variables categóricas, y descubriremos alternativas no paramétricas al t-test y al ANOVA. Esto nos permitirá extraer conclusiones significativas de prácticamente cualquier tipo de dato, abriendo un nuevo y vasto abanico de posibilidades para nuestro análisis exploratorio.