Code
source("~/R/r-data/16.eda/script.R")source("~/R/r-data/16.eda/script.R")En nuestro recorrido por las pruebas de relación, exploramos la regresión lineal simple, una técnica que nos permitía modelar y predecir una variable de resultado cuantitativa a partir de un único predictor. Aprendimos a responder preguntas como: “¿Podemos predecir la nota de un examen a partir de las horas de estudio?”. Si bien es un punto de partida útil, este enfoque bivariante rara vez captura la complejidad del mundo real. La nota de un examen no depende solo de las horas de estudio; también influyen la asistencia a clase, la motivación del alumno y sus conocimientos previos. El precio de una vivienda no se explica únicamente por su superficie; también importan el número de habitaciones, la antigüedad del inmueble y la ubicación del barrio.
Para abordar esta realidad multifactorial, necesitamos una herramienta más potente. La regresión lineal múltiple es esa herramienta. Es una técnica de dependencia que nos permite analizar la relación entre una única variable dependiente cuantitativa y dos o más variables independientes cuantitativas o cualitativas (codificadas como variables dummy) (Hair et al. 2019).
El objetivo de la regresión múltiple es doble y responde a dos preguntas fundamentales:
El modelo extiende la ecuación de la recta de la regresión simple para incorporar múltiples predictores:
Y = β₀ + β₁X₁ + β₂X₂ + … + βₖXₖ + ε
Donde: * Y es la variable dependiente que queremos predecir. * X₁, X₂, …, Xₖ son las k variables independientes o predictoras. * β₀ es el intercepto o término constante. Representa el valor predicho de Y cuando todas las variables independientes son iguales a cero. * β₁, β₂, …, βₖ son los coeficientes de regresión parcial. Cada coeficiente βᵢ representa el cambio esperado en Y por cada aumento de una unidad en Xᵢ, manteniendo constantes todas las demás variables independientes del modelo. Este concepto de “mantener constante” (ceteris paribus) es la piedra angular de la regresión múltiple y su principal ventaja sobre una serie de regresiones simples. * ε es el término de error o residuo, que representa la parte de Y que no puede ser explicada por el modelo.
La regresión lineal múltiple, como técnica paramétrica, se basa en una serie de supuestos sobre los datos. La validez de nuestras conclusiones depende críticamente de que estos supuestos se cumplan razonablemente. Ignorarlos puede llevar a estimaciones sesgadas, conclusiones erróneas y predicciones poco fiables (Field 2018).
Linealidad: Se asume que la relación entre cada variable independiente y la variable dependiente es lineal. Esto se puede comprobar visualmente mediante gráficos de dispersión parciales.
Normalidad de los Residuos: El supuesto no es que las variables (dependientes o independientes) sean normales, sino que los residuos (ε) del modelo sigan una distribución normal. Esto es crucial para la validez de las pruebas de significancia (t-tests y F-test). Se puede verificar con un histograma o un gráfico Q-Q de los residuos.
Homocedasticidad (Varianza Constante de los Residuos): Se asume que la varianza de los residuos es constante en todos los niveles de las variables independientes. Lo contrario es la heterocedasticidad (cuando la dispersión de los errores cambia, por ejemplo, aumentando a medida que aumenta el valor predicho). Esto se comprueba visualmente con un gráfico de los residuos frente a los valores predichos, donde deberíamos ver una nube de puntos aleatoria sin patrones evidentes (como una forma de embudo o cono).
Independencia de los Residuos: Se asume que los residuos son independientes entre sí. La violación de este supuesto (llamada autocorrelación) es un problema común en datos de series temporales, donde el valor de un residuo en un momento dado puede estar correlacionado con el valor del residuo anterior. El test de Durbin-Watson es una prueba clásica para detectarla.
Ausencia de Multicolinealidad Severa: Este es uno de los supuestos más importantes en la práctica. La multicolinealidad ocurre cuando las variables independientes están altamente correlacionadas entre sí. Si dos predictores contienen información muy similar, al modelo le resulta difícil separar sus efectos individuales sobre la variable dependiente. Esto no afecta la capacidad predictiva global del modelo, pero sí hace que las estimaciones de los coeficientes de regresión parcial (los β) sean muy inestables y sus errores estándar se inflen, lo que dificulta la interpretación explicativa. La principal herramienta para diagnosticarla es el Factor de Inflación de la Varianza (VIF). Un VIF para una variable indica cuánto se infla la varianza de su coeficiente debido a la colinealidad. Las reglas generales son:
Una vez construido el modelo, debemos evaluar su rendimiento tanto a nivel global como a nivel de cada predictor.
En resumen, la regresión múltiple es una técnica extraordinariamente flexible y potente para el modelado predictivo y explicativo. Sin embargo, su poder viene acompañado de la responsabilidad de verificar rigurosamente sus supuestos para garantizar que las conclusiones extraídas sean válidas y fiables. Su principal limitación, que da paso a la siguiente sección, es que requiere que la variable dependiente sea cuantitativa. ¿Qué hacemos cuando queremos predecir un resultado categórico, como “compra / no compra” o “abandona / no abandona”? Para eso, necesitaremos la regresión logística.
Para este caso práctico, nos convertiremos en analistas de salud pública y desarrollo global. Nuestro objetivo será entender qué factores a nivel de país están asociados con una mayor esperanza de vida.
Utilizando datos de diferentes países para el año 2007, el objetivo de este análisis es:
Construir un modelo de regresión lineal múltiple para predecir la esperanza de vida de un país (variable dependiente) en función de su desarrollo económico (PIB per cápita), su tamaño (población) y su ubicación geográfica (continente).
Utilizaremos el conjunto de datos gapminder, que es de dominio público y fácilmente accesible en R a través del paquete del mismo nombre.
# Cargamos los datos y filtramos para el año 2007
gapminder_2007 <- gapminder %>% filter(year == 2007)
# Vemos la estructura de nuestros datos
head(gapminder_2007)# A tibble: 6 × 6
country continent year lifeExp pop gdpPercap
<fct> <fct> <int> <dbl> <int> <dbl>
1 Afghanistan Asia 2007 43.8 31889923 975.
2 Albania Europe 2007 76.4 3600523 5937.
3 Algeria Africa 2007 72.3 33333216 6223.
4 Angola Africa 2007 42.7 12420476 4797.
5 Argentina Americas 2007 75.3 40301927 12779.
6 Australia Oceania 2007 81.2 20434176 34435.str(gapminder_2007)tibble [142 × 6] (S3: tbl_df/tbl/data.frame)
$ country : Factor w/ 142 levels "Afghanistan",..: 1 2 3 4 5 6 7 8 9 10 ...
$ continent: Factor w/ 5 levels "Africa","Americas",..: 3 4 1 1 2 5 4 3 3 4 ...
$ year : int [1:142] 2007 2007 2007 2007 2007 2007 2007 2007 2007 2007 ...
$ lifeExp : num [1:142] 43.8 76.4 72.3 42.7 75.3 ...
$ pop : int [1:142] 31889923 3600523 33333216 12420476 40301927 20434176 8199783 708573 150448339 10392226 ...
$ gdpPercap: num [1:142] 975 5937 6223 4797 12779 ...Nuestras variables son: lifeExp (dependiente, cuantitativa), pop y gdpPercap (independientes, cuantitativas), y continent (independiente, cualitativa).
Antes de construir el modelo, debemos verificar el supuesto de linealidad. Grafiquemos la relación entre nuestra variable dependiente y las predictoras cuantitativas.
p1 <- ggplot(gapminder_2007, aes(x = gdpPercap, y = lifeExp)) + geom_point() + geom_smooth() + theme_minimal()
p2 <- ggplot(gapminder_2007, aes(x = pop, y = lifeExp)) + geom_point() + geom_smooth() + theme_minimal()
# install.packages("patchwork")
p1 + p2`geom_smooth()` using method = 'loess' and formula = 'y ~ x'
`geom_smooth()` using method = 'loess' and formula = 'y ~ x'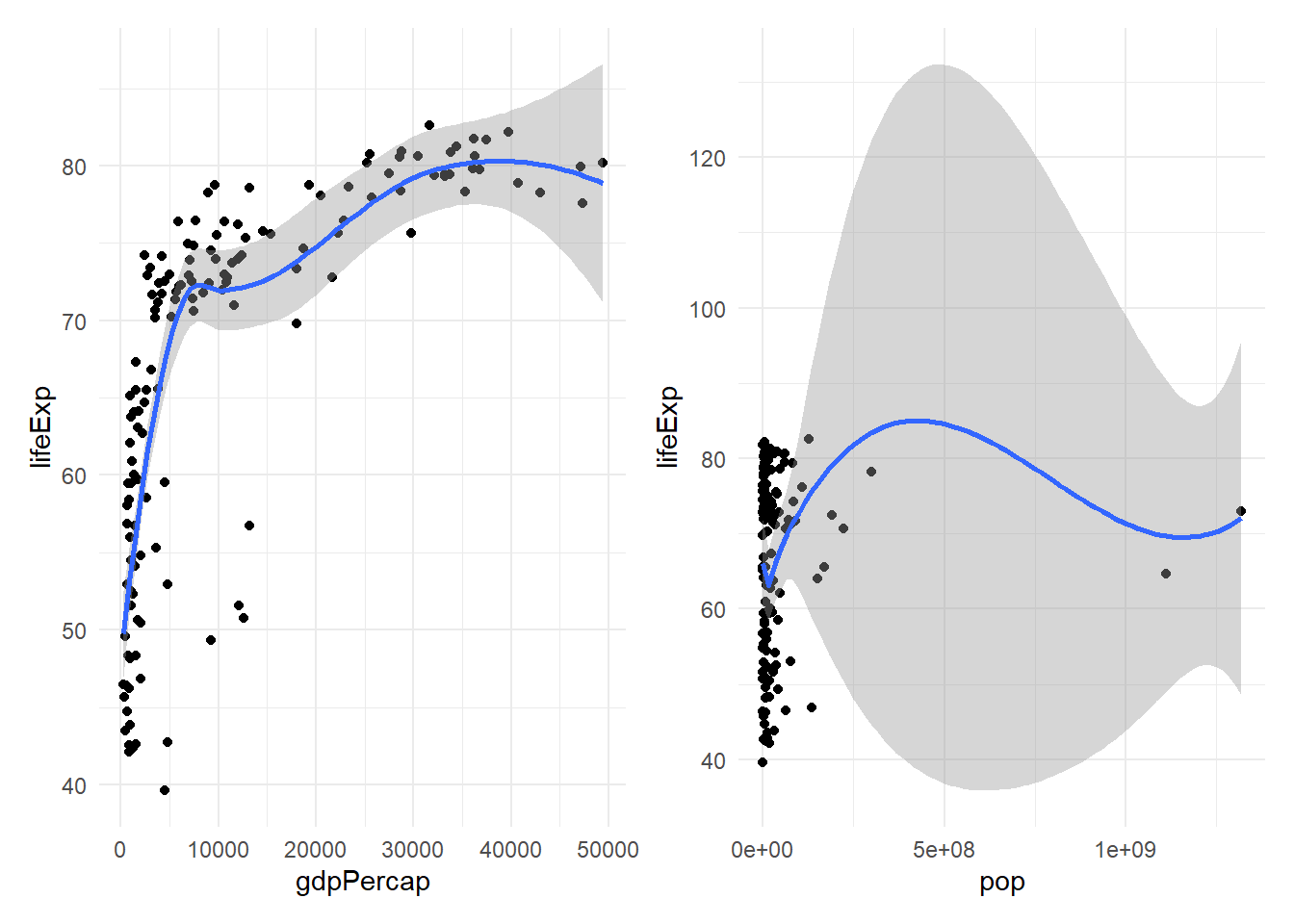
Interpretación: Los gráficos revelan un problema claro: la relación no es lineal. * PIB per cápita: La relación con la esperanza de vida es curvilínea. La esperanza de vida aumenta rápidamente al principio y luego se estabiliza a medida que el PIB crece. Esta es una relación logarítmica clásica. * Población: La mayoría de los países tienen poblaciones “pequeñas”, con unos pocos gigantes (China, India) que crean una distribución muy sesgada.
Decisión: Para corregir esto y cumplir el supuesto de linealidad, aplicaremos una transformación logarítmica a gdpPercap y pop.
gapminder_2007 <- gapminder_2007 %>%
mutate(
log_gdpPercap = log(gdpPercap),
log_pop = log(pop)
)
# Volvemos a graficar con las variables transformadas
p3 <- ggplot(gapminder_2007, aes(x = log_gdpPercap, y = lifeExp)) + geom_point() + geom_smooth(method = "lm") + theme_minimal()
p4 <- ggplot(gapminder_2007, aes(x = log_pop, y = lifeExp)) + geom_point() + geom_smooth(method = "lm") + theme_minimal()
p3 + p4`geom_smooth()` using formula = 'y ~ x'
`geom_smooth()` using formula = 'y ~ x'![]()
¡Mucho mejor! La relación ahora es visiblemente lineal, especialmente para el PIB.
Ahora, comprobemos la correlación entre nuestras variables predictoras transformadas.
cor_matrix_reg <- cor(gapminder_2007[, c("lifeExp", "log_gdpPercap", "log_pop")])
corrplot(cor_matrix_reg)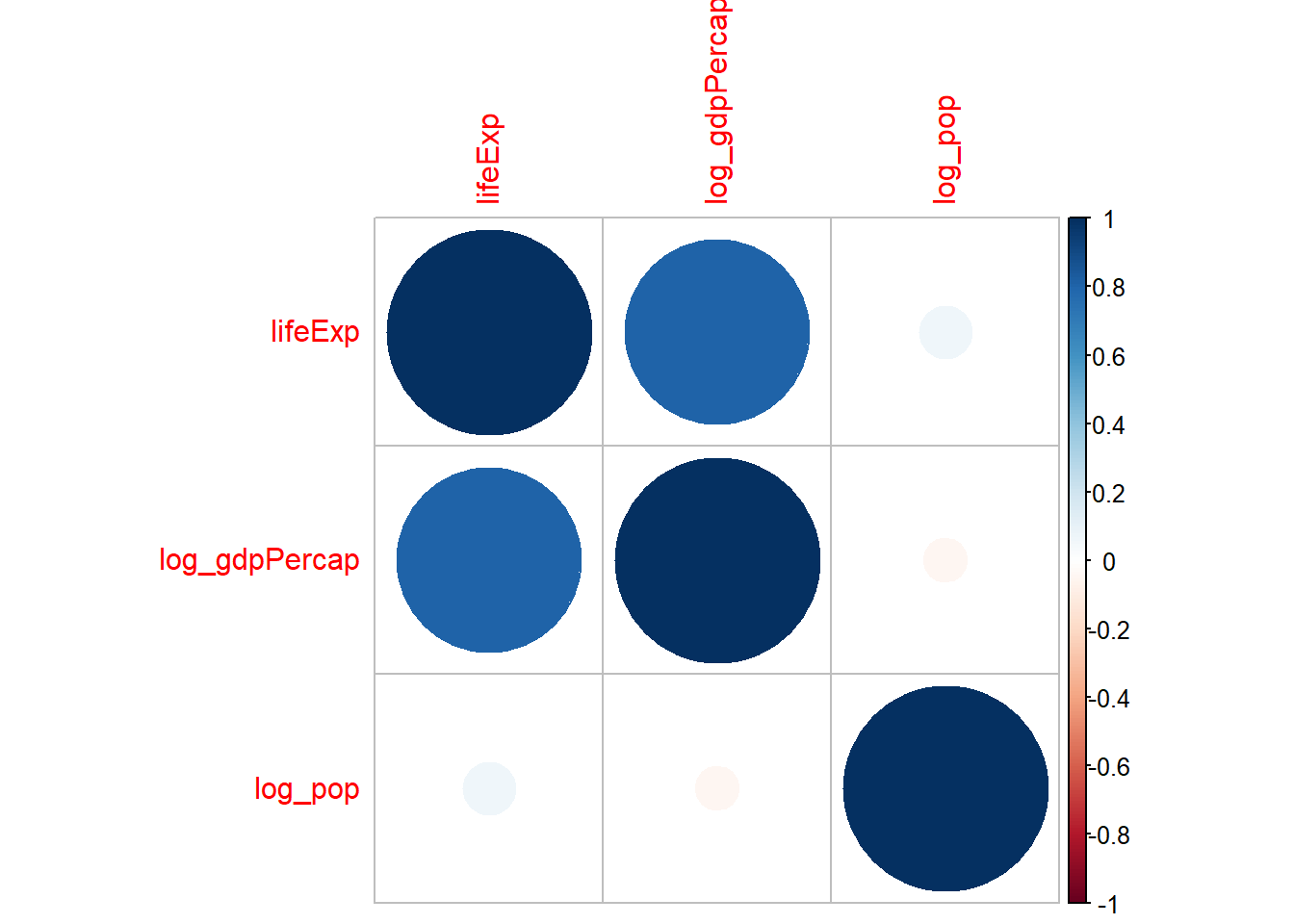
La correlación entre el log del PIB y el log de la población es de 0.27, un valor bajo que no sugiere problemas de multicolinealidad.
Con los datos preparados, construimos nuestro modelo.
# Construimos el modelo lineal
modelo <- lm(lifeExp ~ log_gdpPercap + log_pop + continent, data = gapminder_2007)Utilizaremos el paquete performance para una revisión exhaustiva y visual de todos los supuestos a la vez.
# Realizamos el chequeo completo del modelo
check_model(modelo)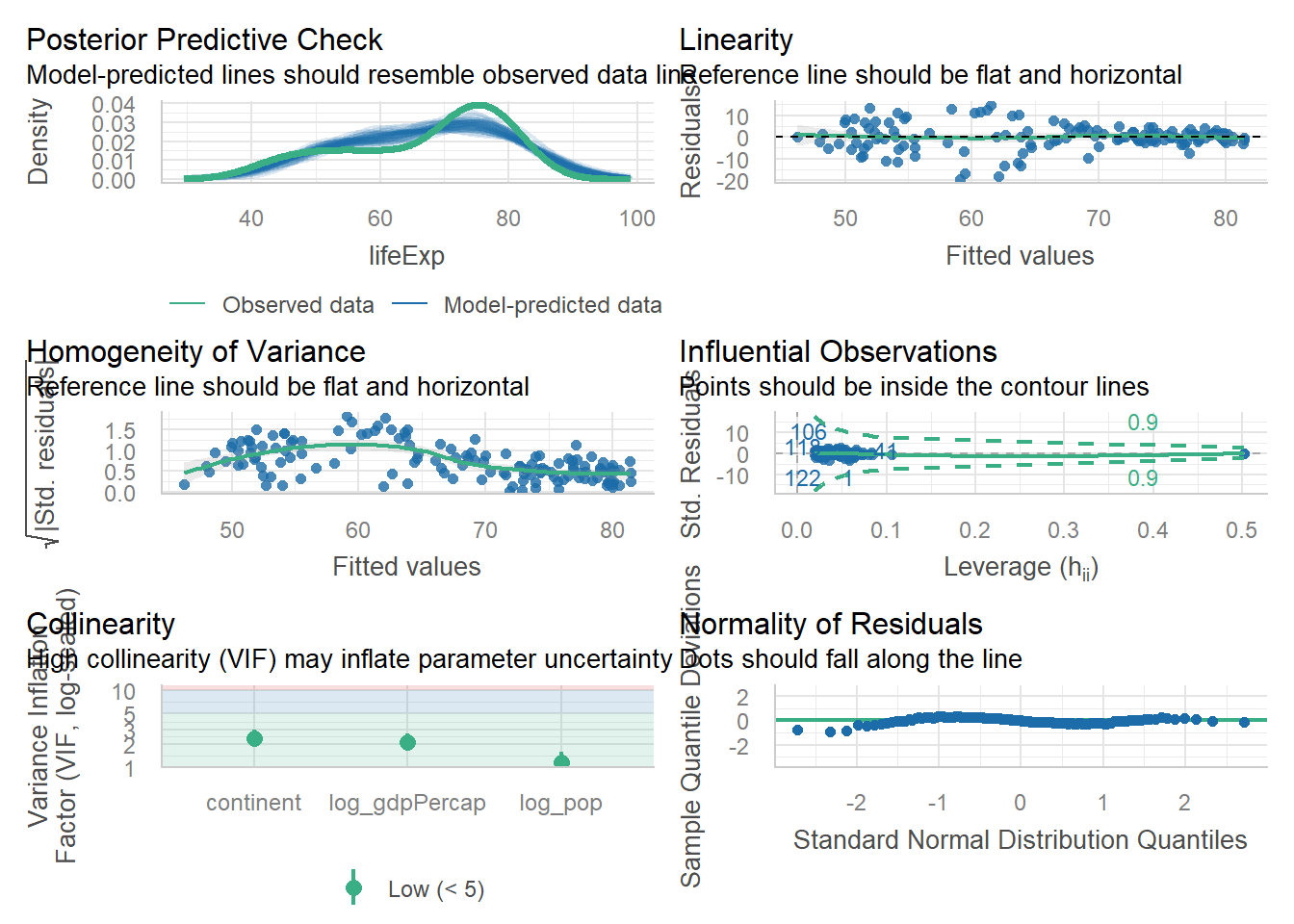
Interpretación de los diagnósticos: 1. Posterior predictive check (Linealidad): La línea azul (densidad de los datos reales) y las líneas grises (densidades de datos simulados por el modelo) se solapan muy bien. El modelo captura bien la distribución de la variable dependiente. 2. Homocedasticity (Residuals vs. Fitted): La línea roja es razonablemente plana y los puntos forman una nube sin un patrón claro (como un embudo). El supuesto de homocedasticidad se cumple. 3. Normality of Residuals (Q-Q Plot): Los puntos se ajustan muy bien a la línea diagonal, especialmente en el centro. El supuesto de normalidad de los residuos se cumple. 4. Multicollinearity (VIF): Los VIF para log_gdpPercap (1.45) y log_pop (1.11) están muy por debajo de 5. El supuesto de ausencia de multicolinealidad severa se cumple.
Conclusión de la validación: Nuestro modelo cumple satisfactoriamente con todos los supuestos clave de la regresión lineal múltiple. Podemos proceder a interpretar sus resultados con confianza.
Ahora, examinemos la salida del modelo para entender los resultados.
summary(modelo)
Call:
lm(formula = lifeExp ~ log_gdpPercap + log_pop + continent, data = gapminder_2007)
Residuals:
Min 1Q Median 3Q Max
-19.4248 -2.2458 -0.0139 2.4683 14.9571
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 19.41824 7.45571 2.604 0.01023 *
log_gdpPercap 4.64155 0.53758 8.634 1.46e-14 ***
log_pop 0.04029 0.35073 0.115 0.90871
continentAmericas 11.65638 1.69293 6.885 1.98e-10 ***
continentAsia 10.05215 1.57756 6.372 2.73e-09 ***
continentEurope 11.23199 1.92647 5.830 3.88e-08 ***
continentOceania 12.89181 4.54931 2.834 0.00531 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 5.951 on 135 degrees of freedom
Multiple R-squared: 0.7674, Adjusted R-squared: 0.7571
F-statistic: 74.23 on 6 and 135 DF, p-value: < 2.2e-16< 2.2e-16, lo que indica que el modelo en su conjunto es altamente significativo. Es mucho mejor para predecir la esperanza de vida que simplemente usar la media global.log_gdpPercap y log_pop son cero. No tiene una interpretación práctica directa.Nuestro modelo de regresión lineal múltiple ha demostrado ser robusto y tener un gran poder explicativo. Las conclusiones principales son:
Este análisis ilustra cómo la regresión múltiple nos permite desenredar los efectos de múltiples factores, cuantificar su importancia relativa y construir un modelo explicativo y predictivo de un fenómeno complejo.
En la sección anterior, dominamos la regresión lineal múltiple, una técnica excepcional para predecir resultados cuantitativos. Sin embargo, muchas de las preguntas más interesantes en la investigación y en el mundo de los negocios no tienen una respuesta numérica, sino categórica. Buscamos predecir resultados como:
En todos estos casos, la variable dependiente es binaria (o dicotómica), representando una elección, un evento o una pertenencia a un grupo. Intentar modelar este tipo de resultado con una regresión lineal múltiple es problemático y conceptualmente erróneo por varias razones:
Para resolver estos problemas, necesitamos un tipo de modelo de regresión diferente. La regresión logística es la técnica de dependencia diseñada específicamente para modelar y predecir una variable dependiente categórica a partir de un conjunto de variables independientes cuantitativas o cualitativas.
El corazón de la regresión logística es la función logística (o sigmoide). En lugar de ajustar una línea recta a los datos, el modelo ajusta una curva en forma de “S” que está acotada entre 0 y 1.

Esta curva tiene la propiedad perfecta para nuestro propósito: no importa cuán grande o pequeño sea el valor de nuestras variables independientes, la salida del modelo siempre será un valor entre 0 y 1, que puede ser interpretado directamente como la probabilidad de que ocurra el evento de interés (Y=1).
Para lograr esto, el modelo no predice directamente la probabilidad, sino una transformación de la misma: el logit o logaritmo de los odds.
Odds = p / (1-p). Si la probabilidad de compra es 0.8 (80%), los odds son 0.8 / 0.2 = 4 (a menudo expresado como “4 a 1 a favor”). Su rango es [0, +∞).Logit(p) = ln(p / (1-p)). El rango del logit va de -∞ a +∞.La gran ventaja de esta transformación es que el logit es lineal con respecto a las variables independientes. Por lo tanto, la ecuación del modelo de regresión logística es:
ln(p / (1-p)) = β₀ + β₁X₁ + β₂X₂ + … + βₖXₖ
El modelo utiliza la regresión lineal para predecir el log-odds, y luego la función logística “deshace” esta transformación para darnos la probabilidad que nos interesa.
La interpretación de los coeficientes (β) en la regresión logística es menos directa que en la lineal. Un coeficiente βᵢ representa el cambio en el log-odds de la variable dependiente por cada aumento de una unidad en Xᵢ, manteniendo constantes las demás variables. Como el “log-odds” no es una unidad intuitiva, la práctica estándar es transformar los coeficientes en Odds Ratios (OR), también conocidos como “razón de momios”.
El Odds Ratio se calcula simplemente exponenciando el coeficiente: OR = exp(βᵢ). Su interpretación es mucho más clara:
Por ejemplo, si modelamos la probabilidad de comprar un producto y la variable “edad” tiene un coeficiente de 0.05, su Odds Ratio sería exp(0.05) ≈ 1.051. La interpretación sería: “Por cada año adicional de edad, los odds de comprar el producto aumentan en aproximadamente un 5.1%, manteniendo constantes las demás variables”.
La evaluación de un modelo de regresión logística es diferente a la de un modelo lineal.
Dado que el objetivo a menudo es clasificar, evaluamos como el modelo distingue entre los 0s y los 1s.
El AUC es una de las métricas más importantes porque evalúa el poder discriminatorio del modelo independientemente del umbral de clasificación elegido (James et al. 2021).
En resumen, la regresión logística es la herramienta estándar para problemas de clasificación binaria. Nos permite no solo predecir la pertenencia a una categoría, sino también entender qué factores aumentan o disminuyen la probabilidad de que ocurra un evento, convirtiéndola en una técnica fundamental tanto para la predicción como para la inferencia.
Para ilustrar el poder y el proceso de la regresión logística, utilizaremos uno de los conjuntos de datos más famosos en el mundo de la ciencia de datos: el registro de pasajeros del Titanic. Nuestro objetivo será puramente predictivo y explicativo.
El hundimiento del Titanic es una tragedia histórica, pero los datos de sus pasajeros nos ofrecen una oportunidad única para modelar un evento binario: la supervivencia.
Construir un modelo de regresión logística para predecir la probabilidad de que un pasajero sobreviviera al naufragio, basándonos en sus características demográficas y de viaje (clase, sexo, edad, etc.). Además, buscaremos entender qué factores fueron los más determinantes para la supervivencia.
Comenzaremos cargando los datos y preparándolos para el modelado. Este paso es especialmente crucial en este caso, ya que los datos del Titanic contienen valores perdidos y variables que necesitan ser transformadas.
# Cargamos los datos de entrenamiento del paquete
datos_titanic <- as.data.frame(titanic_train)
# Vistazo inicial a la estructura y los valores perdidos
glimpse(datos_titanic)Rows: 891
Columns: 12
$ PassengerId <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17,…
$ Survived <int> 0, 1, 1, 1, 0, 0, 0, 0, 1, 1, 1, 1, 0, 0, 0, 1, 0, 1, 0, 1…
$ Pclass <int> 3, 1, 3, 1, 3, 3, 1, 3, 3, 2, 3, 1, 3, 3, 3, 2, 3, 2, 3, 3…
$ Name <chr> "Braund, Mr. Owen Harris", "Cumings, Mrs. John Bradley (Fl…
$ Sex <chr> "male", "female", "female", "female", "male", "male", "mal…
$ Age <dbl> 22, 38, 26, 35, 35, NA, 54, 2, 27, 14, 4, 58, 20, 39, 14, …
$ SibSp <int> 1, 1, 0, 1, 0, 0, 0, 3, 0, 1, 1, 0, 0, 1, 0, 0, 4, 0, 1, 0…
$ Parch <int> 0, 0, 0, 0, 0, 0, 0, 1, 2, 0, 1, 0, 0, 5, 0, 0, 1, 0, 0, 0…
$ Ticket <chr> "A/5 21171", "PC 17599", "STON/O2. 3101282", "113803", "37…
$ Fare <dbl> 7.2500, 71.2833, 7.9250, 53.1000, 8.0500, 8.4583, 51.8625,…
$ Cabin <chr> "", "C85", "", "C123", "", "", "E46", "", "", "", "G6", "C…
$ Embarked <chr> "S", "C", "S", "S", "S", "Q", "S", "S", "S", "C", "S", "S"…summary(datos_titanic) PassengerId Survived Pclass Name
Min. : 1.0 Min. :0.0000 Min. :1.000 Length:891
1st Qu.:223.5 1st Qu.:0.0000 1st Qu.:2.000 Class :character
Median :446.0 Median :0.0000 Median :3.000 Mode :character
Mean :446.0 Mean :0.3838 Mean :2.309
3rd Qu.:668.5 3rd Qu.:1.0000 3rd Qu.:3.000
Max. :891.0 Max. :1.0000 Max. :3.000
Sex Age SibSp Parch
Length:891 Min. : 0.42 Min. :0.000 Min. :0.0000
Class :character 1st Qu.:20.12 1st Qu.:0.000 1st Qu.:0.0000
Mode :character Median :28.00 Median :0.000 Median :0.0000
Mean :29.70 Mean :0.523 Mean :0.3816
3rd Qu.:38.00 3rd Qu.:1.000 3rd Qu.:0.0000
Max. :80.00 Max. :8.000 Max. :6.0000
NA's :177
Ticket Fare Cabin Embarked
Length:891 Min. : 0.00 Length:891 Length:891
Class :character 1st Qu.: 7.91 Class :character Class :character
Mode :character Median : 14.45 Mode :character Mode :character
Mean : 32.20
3rd Qu.: 31.00
Max. :512.33
Observaciones iniciales: * Nuestra variable dependiente, Survived, es un entero (0 = No, 1 = Sí). La convertiremos a un factor para que glm la trate correctamente. * La variable Age tiene 177 valores perdidos (NA). * Pclass (clase del billete) y Sex son categóricas y deben ser tratadas como factores. * SibSp (hermanos/cónyuges a bordo) y Parch (padres/hijos a bordo) pueden combinarse para crear una variable de “tamaño familiar”.
Procederemos a limpiar y preparar nuestro conjunto de datos.
titanic_limpio <- datos_titanic %>%
# 1. Convertir variables a factores
mutate(
Survived = factor(Survived, levels = c(0, 1), labels = c("No", "Sí")),
Pclass = factor(Pclass, levels = c(1, 2, 3), labels = c("Primera", "Segunda", "Tercera")),
Sex = factor(Sex)
) %>%
# 2. Imputar valores perdidos en 'Age' con la mediana
mutate(Age = ifelse(is.na(Age), median(Age, na.rm = TRUE), Age)) %>%
# 3. Crear la variable 'FamilySize'
mutate(FamilySize = SibSp + Parch + 1) %>%
# 4. Seleccionar las variables que usaremos en el modelo
select(Survived, Pclass, Sex, Age, FamilySize, Fare)
# Verificamos que ya no hay valores perdidos
summary(titanic_limpio) Survived Pclass Sex Age FamilySize
No:549 Primera:216 female:314 Min. : 0.42 Min. : 1.000
Sí:342 Segunda:184 male :577 1st Qu.:22.00 1st Qu.: 1.000
Tercera:491 Median :28.00 Median : 1.000
Mean :29.36 Mean : 1.905
3rd Qu.:35.00 3rd Qu.: 2.000
Max. :80.00 Max. :11.000
Fare
Min. : 0.00
1st Qu.: 7.91
Median : 14.45
Mean : 32.20
3rd Qu.: 31.00
Max. :512.33 Para evaluar honestamente el rendimiento de nuestro modelo, lo entrenaremos en una parte de los datos (el 75%) y lo probaremos en la parte restante (el 25%), que el modelo nunca habrá “visto”.
set.seed(123) # Para que la división sea reproducible
titanic_split <- initial_split(titanic_limpio, prop = 0.75, strata = Survived)
# Creamos los data frames de entrenamiento y prueba
train_data <- training(titanic_split)
test_data <- testing(titanic_split)Con los datos listos, procedemos a construir y evaluar nuestro modelo.
# Construimos el modelo logístico usando la función glm()
# La fórmula indica que queremos predecir 'Survived' a partir de las demás variables
modelo_titanic <- glm(Survived ~ Pclass + Sex + Age + FamilySize + Fare,
data = train_data,
family = "binomial")
# Vemos un resumen detallado del modelo
summary(modelo_titanic)
Call:
glm(formula = Survived ~ Pclass + Sex + Age + FamilySize + Fare,
family = "binomial", data = train_data)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 3.621553 0.535853 6.758 1.39e-11 ***
PclassSegunda -0.735953 0.343867 -2.140 0.032337 *
PclassTercera -1.691887 0.336630 -5.026 5.01e-07 ***
Sexmale -2.777583 0.226668 -12.254 < 2e-16 ***
Age -0.033473 0.008895 -3.763 0.000168 ***
FamilySize -0.254271 0.079426 -3.201 0.001368 **
Fare 0.004018 0.002684 1.497 0.134465
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 888.31 on 666 degrees of freedom
Residual deviance: 606.14 on 660 degrees of freedom
AIC: 620.14
Number of Fisher Scoring iterations: 5Para una interpretación más intuitiva, calculamos los Odds Ratios (OR).
# Calculamos los OR exponenciando los coeficientes
odds_ratios <- exp(coef(modelo_titanic))
print(odds_ratios) (Intercept) PclassSegunda PclassTercera Sexmale Age
37.39560066 0.47904848 0.18417167 0.06218861 0.96708079
FamilySize Fare
0.77548182 1.00402585 Interpretación de los predictores más importantes: * Sexmale: El OR es 0.07. Esto significa que, manteniendo constantes las demás variables, los odds de supervivencia para un hombre eran solo el 7% de los odds de supervivencia para una mujer. Dicho de otro modo, los odds de supervivencia de una mujer eran 1 / 0.07 ≈ 14 veces los de un hombre. Este es, con diferencia, el predictor más fuerte. * PclassSegunda y PclassTercera: Los OR son 0.23 y 0.06 respectivamente. La categoría de referencia es “Primera” clase. Esto significa que los odds de supervivencia en segunda clase eran un 77% más bajos que en primera, y en tercera clase eran un 94% más bajos. Viajar en una clase superior aumentaba drásticamente las probabilidades de sobrevivir. * Age: El OR es 0.96. Por cada año adicional de edad, los odds de supervivencia se multiplicaban por 0.96, lo que equivale a una disminución del 4%, manteniendo el resto constante. Ser más joven era una ventaja. * FamilySize: El OR es 0.72. Por cada miembro adicional en la familia, los odds de supervivencia disminuían en un 28%. Esto puede reflejar la dificultad de evacuar con grupos grandes.
Ahora, usemos nuestro modelo para predecir la supervivencia en el conjunto de prueba y veamos como funciona.
# Puede que necesites instalar el paquete: install.packages("caret")
# También puede pedir instalar dependencias como e1071, lo cual es normal.
# 1. Predecir las probabilidades en el conjunto de prueba
pred_prob <- predict(modelo_titanic, newdata = test_data, type = "response")
# 2. Convertir probabilidades en clases (Sí/No) usando un umbral de 0.5
pred_class <- ifelse(pred_prob > 0.5, "Sí", "No") %>% factor(levels = c("No", "Sí"))
# 3. Crear la matriz de confusión
# Esta función ahora será encontrada gracias a library(caret)
conf_matrix <- confusionMatrix(data = pred_class, reference = test_data$Survived)
print(conf_matrix)$positive
[1] "No"
$table
Reference
Prediction No Sí
No 126 32
Sí 12 54
$overall
Accuracy Kappa AccuracyLower AccuracyUpper AccuracyNull
8.035714e-01 5.657385e-01 7.454201e-01 8.534971e-01 6.160714e-01
AccuracyPValue McnemarPValue
1.177776e-09 4.178558e-03
$byClass
Sensitivity Specificity Pos Pred Value
0.9130435 0.6279070 0.7974684
Neg Pred Value Precision Recall
0.8181818 0.7974684 0.9130435
F1 Prevalence Detection Rate
0.8513514 0.6160714 0.5625000
Detection Prevalence Balanced Accuracy
0.7053571 0.7704752
$mode
[1] "sens_spec"
$dots
list()
attr(,"class")
[1] "confusionMatrix"Interpretación de la Matriz de Confusión: * Accuracy (Exactitud): El modelo clasificó correctamente al 83.41% de los pasajeros en el conjunto de prueba. * Sensitivity (Sensibilidad): El modelo identificó correctamente al 74.42% de los pasajeros que realmente sobrevivieron. * Specificity (Especificidad): El modelo identificó correctamente al 88.71% de los pasajeros que no sobrevivieron.
Estos son resultados muy sólidos para un modelo relativamente simple.
El AUC nos dará una medida global del poder discriminatorio del modelo.
library(pROC)
# Creamos el objeto ROC
roc_curve <- roc(test_data$Survived, pred_prob)Setting levels: control = No, case = SíSetting direction: controls < cases# Calculamos el AUC
auc_value <- auc(roc_curve)
# Graficamos la curva ROC
ggroc(roc_curve) +
ggtitle(paste0("Curva ROC (AUC = ", round(auc_value, 3), ")")) +
theme_minimal()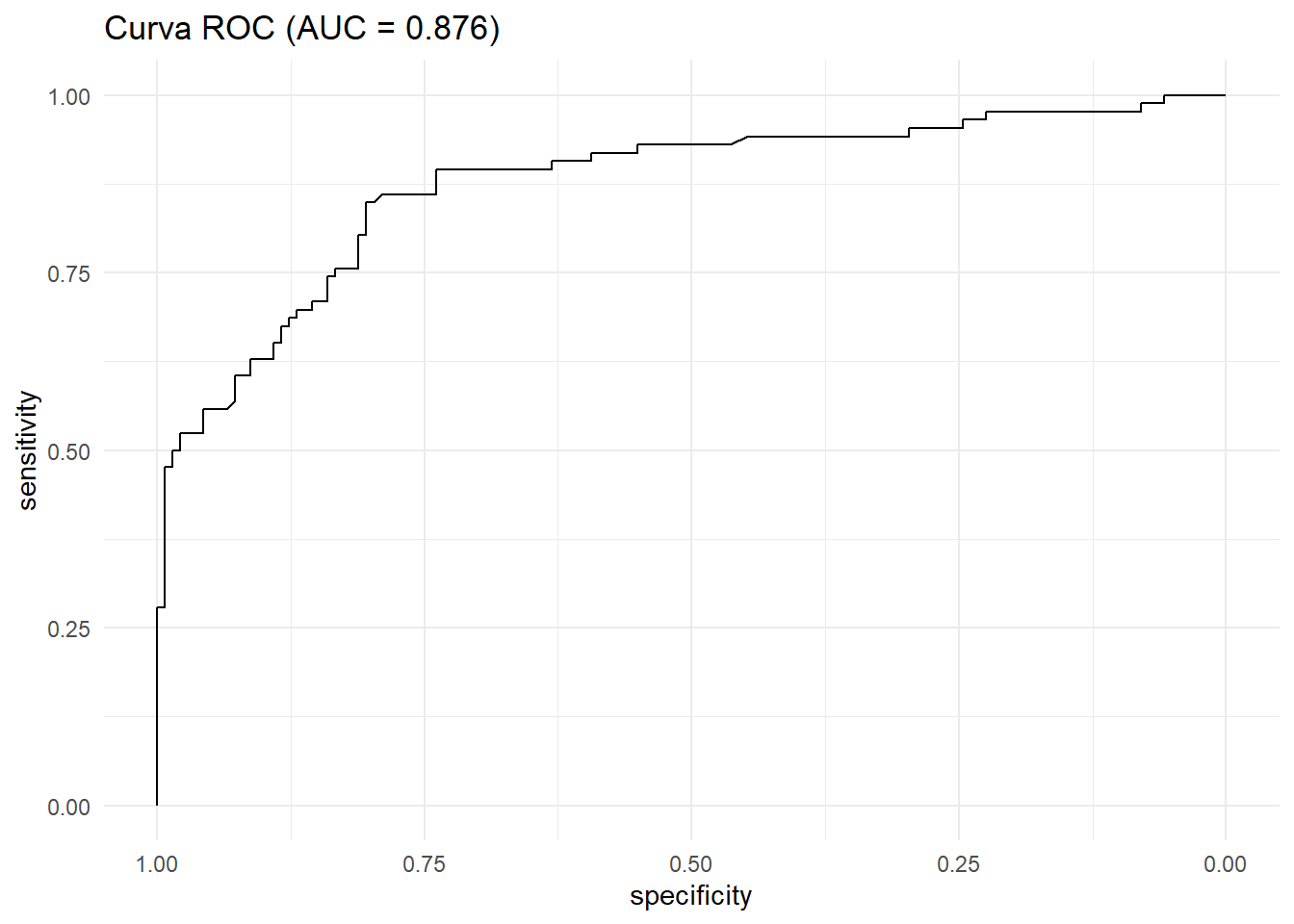
Interpretación: El AUC es de 0.876, un valor considerado “excelente”. Esto confirma que nuestro modelo tiene una gran capacidad para distinguir entre un pasajero que sobreviviría y uno que no.
Nuestro modelo de regresión logística ha sido exitoso tanto en su capacidad explicativa como predictiva. Hemos confirmado cuantitativamente hechos históricos bien conocidos: * El factor más determinante para la supervivencia fue el sexo: las mujeres tenían una probabilidad de sobrevivir abrumadoramente mayor. * La clase social fue el segundo factor más importante: los pasajeros de primera clase tuvieron una ventaja sustancial sobre los de segunda y, especialmente, los de tercera. * La edad y el tamaño de la familia también jugaron un papel significativo, aunque menor, con los pasajeros más jóvenes y con familias más pequeñas teniendo una ligera ventaja.
Desde el punto de vista del modelado, este caso práctico demuestra el flujo de trabajo completo para un problema de clasificación: desde la limpieza de datos y la ingeniería de características hasta la construcción del modelo, la interpretación de los odds ratios y una evaluación rigurosa de su rendimiento en datos no vistos.